What makes good code good at INTECOL13
What makes good code good at INTECOL13
 By Mike Jackson.
By Mike Jackson.
On 21st August, I attended INTECOL13 in London's Docklands. The 11th International Congress of Ecology, hosted by the British Ecological Society and INTECOL, is one of the world's premier conference for ecologists.
At the invitation of Matthew Smith from the BES Computational Ecology Specialist Interest Group and Microsoft Research, and Greg Wilson from Software Carpentry, I ran the latest instalment of The Software Sustainability Institute's what makes good code good discussions...
I'd expected about 20 attendees and was pleasantly surprised (nay, stunned) when about 100 turned up. Fortunately, Matthew and my Institute colleagues, Carole Goble and Steve Crouch, were on hand to help as was Daniel Falster, a Software Carpentry instructor from Macquarie University, Australia. And given there was only one flip chart available, I was glad I'd packed a good supply of sticky notes.
Most of the attendees classed themselves as scientists who do some scripting or coding, with about half a dozen scientific programmers and another half a dozen software developers. After discussing in groups, the attendees proposed that good code should be:
- Readable. Code should be well presented and indented, with understandable names for functions and variables. It should also be well-commented (e.g. functions describe their inputs and outputs). Naming, indentation and comments should also be internally consistent.
- Well-designed. Code should be modular and have a logical structure. Modules should be reusable. Repeated code should be avoided and instead pulled out into functions, conforming to the design heuristic DRY: Don't Repeat Yourself. A good design takes time and this should be invested before starting to write code. Design may take into account whether there will be any intention to exploit parallel processing, as it is significantly less effort to parallelize a code that has been designed to exploit parallelism than to parallelise one that hasn't (which may incur a complete rewrite of the code).
- Correct. Code must produce the right results, so that researchers can have confidence in it, and the results derived from it. Code should be supported by tests, as these can help to demonstrate correctness. Ideally, code should also be subject to some form of peer review or inspection.
- Robust. Code should be resilient and handle scenarios outwith expected usage (e.g. incorrect input values). Code should fail gracefully, with appropriate and informative error messages. It should also have built-in support for debugging and, ideally, this should include some form of visualisation.
- Efficient. Code should be efficient in its use of CPU and memory. However, there can be trade-offs between efficiency and readability.
- Flexible. Relating to good design, code should be flexible, adaptable and reusable, not just by the original developer, but for others outwith the project.
- Documented. Code should come with good supporting user documentation and case studies. These should not just be about how the code works, but how another researcher can use it, for their problems. Versions of third-party technologies, languages and libraries required should also be clearly documented to help others build and use it more easily.
- Use open technologies, languages, dependencies. These are often available at lower cost, or free, as opposed to commercial packages and their use can remove one barrier to the adoption of the code.
- Referencable. Code should be referencable and citable and not necessarily require a supporting journal or conference paper.
- Under revision control. Code should be held under revision control so that all the changes that have been made to it, its provenance, is recorded.
- Available. Code should be open and available e.g. on GitHub, to allow other researchers both to use it and to review it.
- Usable. Code should be easy to use by other researchers.
- Benchmarked. Code should be accompanied by benchmarks to allow users to understand its efficiency and scalability and whether it is suitable for their requirements.
A tally of the votes for each category, from the content of the sticky notes filled in by each group of attendees, is shown in the following pie chart.
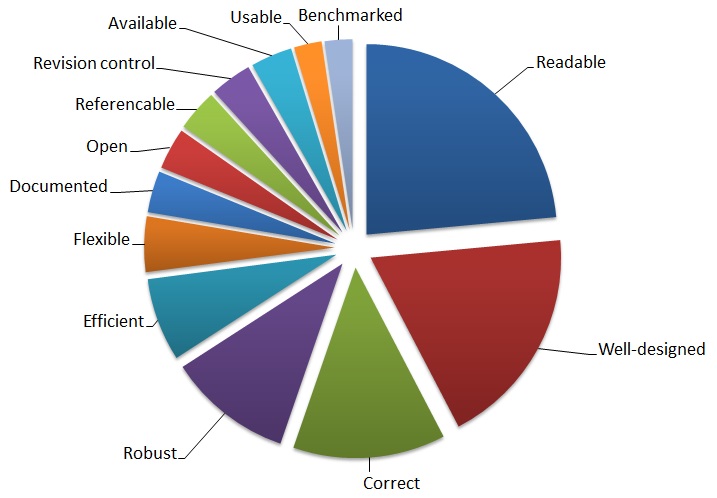
The responses and the focus on readability, clarity and correctness, overlap closely with commonly-understood definitions of good code as taught on software development courses or expressed in numerous articles and blogs (see, for example, What makes good code good by Paul DiLascia, MSDN Magazine, 07/2004, p144, or Christopher Diggins's The Properties of Good Code, 27/09/2005).
A number of blockers that can inhibit producing good code were also suggested. These included:
- Writing code for me. Many researchers write code for their own research to produce the results they need, and won't spend the time making their code readable and usable by others. Often this comes down to a...
- Lack of time. Researchers have many demands on their time and making code good is often sacrificed to these other demands, especially authoring journal or conference papers. This can be a consequence of a...
- Lack of reward. Researchers are judged on their research outputs, which are primarily papers. As code does not currently have the same statute as a journal paper, for example, it is understandable that researchers may invest less time on it.
- Lack of training. Researchers may not have access to the training they might need to write good code. As one attendee commented, "Where is 'Error messages 101?'".
- No local experts. Researchers may not have local experts on-hand to help and share expertise. This could be provided by an institution-wide team of dedicated experts (for example research software engineers). However, even an agreement amongst a group of researchers to use the same languages and technologies can help a peer support group to evolve.
- How to couple models, papers, code and documentation. A paper documents a model used for research, the code implements that model, and documentation describes the implementation. What is the best way to couple these artefacts together? What is needed for reusable, reproducible, reviewable research?
- Lack of awareness of what already exists. Often researchers don't know what tools already exist, or even where to find out whether there are such tools. As a result they may invest precious project resources reinventing the wheel.
- Tools that almost do the job. There are often a number of related tools that can satisfy a researcher's requirements. However, each of these may do similar things in slightly different ways so the researcher either has to use more than one or may even write their own to do exactly what they need. How can such divergence be resolved? How can related projects be encouraged to work together?
A big thank you to Matthew and Greg for inviting the Institute to run the session, the INTECOL13 organisers for allowing us to do so, Carole, Steve, Matthew and Daniel for helping out, and the attendees themselves for taking part and sharing their time, experiences and opinions.