

What do you tell your PhD student Three Years Before They Leave …
 By Vince Knight, Cardiff University, Olivia Wilson, University of Southampton, Shoaib Sufi, Software Sustainability Institute, Steve Crouch, Software Sustainability Institute, and Ian Gent, University of St Andrews.
By Vince Knight, Cardiff University, Olivia Wilson, University of Southampton, Shoaib Sufi, Software Sustainability Institute, Steve Crouch, Software Sustainability Institute, and Ian Gent, University of St Andrews.
A speed blog from the Collaborations Workshop 2016 (CW16).
"Congratulations Dr Smith"
The words every PhD student dreams of hearing, at least if your name is Smith. First from your examiners, and then soon afterwards from your supervisor. And then those words every PhD student dreads of hearing from your supervisor…
"Just before you go to your super-rich quant futures job on Wall Street, could you just …
…. hand over your code to my new PhD student please?"You remember the same conversation three years ago, when you saw your predecessor Dr Jones stammer and make excuses, and promise to send their code to you "in a few weeks after I’ve tidied it up." You suppose technically that 156 weeks might be described as "a few weeks" but certainly you’ve never seen that software. Software that was good enough to get a PhD for Dr Jones, but not good enough to pass on to the next student. All you can say is
"No, I’m sorry Prof Patel, I can’t hand it on,... ".
What should Prof Patel have said three years ago so that Dr Smith would have no problem handing over their code?
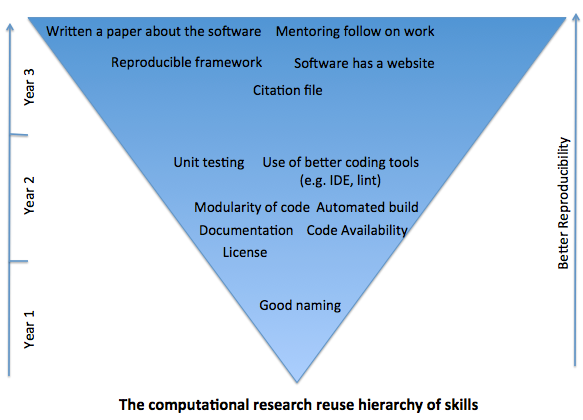
There are many issues that can help any PhD student write code which will be easy to pass on, and which will make it easy for other researchers to reproduce. We call these the “computational research reuse hierarchy of skills”. They go from some quite low level issues to some very high level ones. Here are some of the more low level ones.
Making your code readable is just important as making sure it executes correctly. As such one of the fundamental aspects of writing reproducible software is best practice with regards to naming of functions and variables. This is very well explained in the opening chapters of Martin (2009). Whilst, in Mathematics, using variables like $x$ and $y$ is perfectly normal and acceptable: one reads a Mathematical argument from start to finish but these choices of names would be very confusing in software. One does not read software from start to finish as an argument. For example, the following makes no sense whatsoever:
s = 0 for i in l: if i.b: s += i.cHowever, modifying that to make it clear as to what the code would do:
number_of_customers = 0 for vehicle in buses: if vehicle.is_red: number_of_customers += vehicle.passengersThe above code will get a count of the number of customers that have used red buses. This simple change is not syntaxic but simply a question of choosing verbose variable names. This simple aspect is a best practice idea that extends to function, class and module names. There are no extra points for writing short code.
When using verbose and explicit names for things the code in essence starts to be its own documentation. This leads to the another aspect of the hierarchy of software needs: documentation of code. Code should be documented: comments and docstrings explaining the why of pieces of code once again help for the readability and thus eventually reuse of software.
Coming back to your own code and working out what individual lines do can be the most challenging task of all. There seems to be a line of code that doesn't do anything but the minute you take it out your entire script fails in a major way. Most people will advocate comments in your code of what the code is doing but what will help you in this scenario is why you wrote the code to do that. Good variable naming is one way of doing this, building on this we have docstrings. These explain the purpose of a function (using the above example):
def count_red_bus_passengers(buses): """Takes a buses object and counts the number of passengers on red buses. Args ---- Buses: buses object The object to count the passengers Returns ------- Number_of_customers: int The number of customers on each red bus Notes ----- This will only return if there are some red vehicles in the buses object """ # Makes sure that the number of customers is set to zero number_of_customers = 0 # Takes each vehicle in the buses object # and adds together the number of passengers in each vehicle for vehicle in buses: if vehicle.is_red: number_of_customers += vehicle.passengers
So here we have a well documented piece of code (in Python) that explains what it does (beginning of docstring), why it does things (comments) and what kind of things is takes in. This means people will know that it won’t take cars object and that it gives you a number as a result.
When writing docstrings -- as with writing code itself -- write with the intent of being read. As such one of the important aspects of reusability of code is availability of code. It is important to make code (especially research code) available. This can be done by putting it on a public GitHub repository or perhaps just shared on an internal server. This is not done with a simply altruistic motive (of making code useful to others) but also of ensuring other users might read the code and suggest improvements. This is especially important at the start of one’s journey through the hierarchy of needs and leads on to other ideas such as pair programming.
What we are describing is a hierarchy of skills (as illustrated by the image above). How and where one enters the pyramid as well as how far up they go are important considerations. For example a primary school student learning scratch would not need to learn fundamental aspects of version control.
Our story has a happy ending. After their bad experience with Dr Jones, Prof Patel advised Smith so well that there was no problem at all.
"No, I’m sorry Prof Patel, I can’t hand it on. Your new PhD student already has full access to my code repository, has added lots of tests, submitted pull requests that I have accepted, and has made sure that the build system works on their machine without intervention. Thanks so much for giving me all that advice to me when I started three years ago."
Martin, Robert C. Clean code: a handbook of agile software craftsmanship. Pearson Education, 2009.