Recognising software is central to science: the Code/Theory Workshop makes the case

Recognising software is central to science: the Code/Theory Workshop makes the case
 By Caroline Jay, University of Manchester, Robert Haines, University of Manchester.
By Caroline Jay, University of Manchester, Robert Haines, University of Manchester.
A group of research software engineers (RSEs) recently gathered in Manchester, to explore the challenges of translating between scientific narrative and software. The full report from the Code/Theory Workshop is available in Research Ideas and Outcomes; here, we summarise the outcomes of the afternoon. Software engineers are sometimes seen as peripheral to the academic enterprise, providing the tool to do research, rather than actively contributing to the research itself. The overwhelming conclusion of the workshop was that, in reality, software engineers play a central role in the research process, and it is vital to get this message across.
Why is code/theory translation challenging?
Participants started by identifying the challenges of translating between code and theory. A key theme that emerged was the difficulty of designing research software. As scientific theory is continually changing, how do you design a plan?
All participants faced the challenge of getting to grips with new and diverse domains. In some projects, RSEs were not invited to meetings where 'the science' was discussed, as their expertise was not viewed as relevant. As a result, it was often a struggle to understand the nuances of the science they were trying to implement in code.
It was common for the non-developers in a project (who may be academics, or other users), to have a poor understanding of the software engineering process. Participants reported struggling with investigators who had preconceived ideas and expected unrealistic outcomes. The fact that building software was not regarded as valuable was also a common complaint: significant amounts of money are spent on facilities and equipment, but less thought is given to software. There was a perception that researchers typically want something that works quickly, independent of its quality. There was a lack of appreciation for the skill that software development requires, and that there would be a relationship between the quality of the code, and the quality of the results.
Participants noted there was a misunderstanding not just of software engineering, but of computation itself. Software was viewed as a trusted 'black box', blaming unexpected results on bad data. There should be wider recognition that the software produced for research is not necessarily perfect.
A researcher used to traditional statistical solutions might want to view results as concrete, but in reality, the results will depend on the implementation. Evaluation of software representing theory was critical, but also very difficult. Instances were cited of people choosing to 'believe' the software outputs over data obtained through real experimentation.
A final issue noted was that understanding software was also a problem for RSEs: code created to model theory or advanced science is often highly complex, and even those who create it can struggle to understand its intricacies and behaviour.
How can we improve code/theory translation?
In the second session, participants considered potential solutions to the challenges that emerged in the previous discussion. Everyone agreed that the best science happened in cohesive teams and that the 'human element' was an essential but elusive ingredient for success. Co-locating people in different roles such that they could talk regularly, and get used to each other's technical language was viewed as essential, particularly in interdisciplinary research.
Training in software engineering skills early in the research process was viewed as essential. At present there is a perception within some research groups that by the end of a PhD people will have enough computational knowledge to do robust research without software engineering experts, but it was felt that in reality, many researchers' skills remain woefully inadequate.
Software has the potential to be both a means of facilitating, and an outcome of, research. While the written expression of theory (words or formalisms) is constructed for human understanding, and lab equipment has an obvious physical presence, software is difficult for humans to read and understand, and intangible - essentially, unseeable, and unknowable. Even if software is openly available, people may not appreciate what it is doing, and how important it is. Formally recognising the role of software engineering—and software engineers—was viewed as very helpful in this regard. As one participant stated: 'if you've only ever seen what can be achieved by a 'code-savvy' PhD student then seeing what a room full of RSEs can do will be revelatory.'
Interesting questions that arose here included: how do we raise the profile of research software?; to what extent do people need to understand the software to understand the science?; how do we balance opening code and the need to commercialise? There was a view that publishers and funding agencies should push for code to be open, but there was also a concern that current publication models are effectively a thin paper wrapper around software. Academia should look beyond the paper to acknowledge the value in software: having software as a second class citizen is dangerous given its central role in the research process.
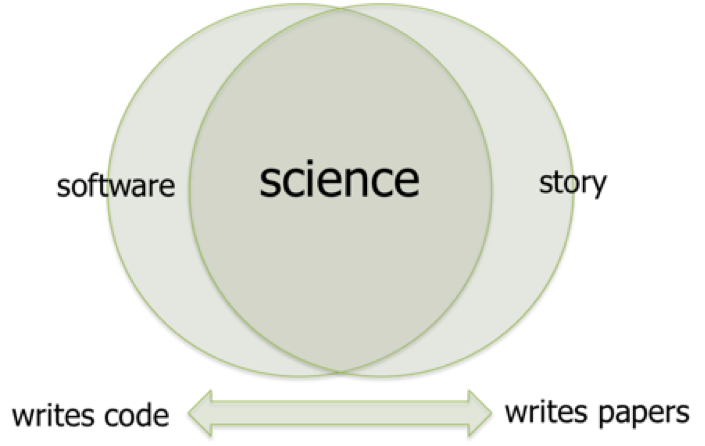
Image: In many areas, science is produced at the intersection of the 'software', contributed by programmers, and the 'story', or theoretical narrative, contributed by domain experts. In team-based research, everyone is a scientist.
Conclusions
The overwhelming message from this first Code/Theory workshop was that science is a team effort, and cohesive working across everyone involved in a research project was essential to its success. While this in itself is not a surprising conclusion, it is probably true to say that from the perspective of many of the RSEs, it was not always reflected in the reality of their experience. This may be an artefact of the academic environment. Software is not currently valued in the same way as more tangible expressions of theory, such as words or mathematics, and as such, software engineering is not valued in the same way as better understood parts of the research process.
RSEs do not write code in a vacuum, but play a key role in research activities: hypothesis generation; study design; data analysis; interpretation of results. Everyone in a research team is essential to its success, and while there is a natural division of labour between RSEs - who spend more time writing code - and other researchers - who spend more time writing papers - all of this work is core to the scientific endeavour. While some of us work on the software necessary to produce results, and others work on the surrounding story necessary to explain them, in team-based research we are all scientists. Recognising this fact, and embedding this message in academic discourse, is key to securing the future of research.
References
Jay C, Haines R, Vigo M, Matentzoglu N, Stevens R, Boyle J, Davies A, Del Vescovo C, Gruel N, Le Blanc A, Mawdsley D, Mellor D, Mikroyannidi E, Rollins R, Rowley A, Vega J (2017) Identifying the challenges of code/theory translation: report from the Code/Theory 2017 workshop. Research Ideas and Outcomes 3: e13236.
Acknowledgements
We would like to thank the Software Sustainability Institute for funding the workshop via Caroline Jay's 2016 Fellowship.