GUIs for research software: Why are they relevant? (part one)
GUIs for research software: Why are they relevant? (part one)
By Diego Alonso Álvarez, Senior RSE, Research Computing Service-ICT, Imperial College London.
This is the first part of of this blog post. Read the second part here.
Research software has been a driving force behind the birth and rapid growth of informatics, but it was the appearance of graphical user interfaces (GUI) in the 1980s that made computers accessible to everyone. A GUI helps to reduce the learning curve for using software, increases the base of potential users and can ultimately increase citations and impact. Moreover, a well-designed GUI can perform validation and increase the robustness and reproducibility of the results, productively decoupling developers from users.
This blog post is the first of a series of entries devoted to help developers lose their fear - or reluctance - to invest time creating a GUI for their research software, and help them to take those first steps in the development of graphical user interfaces.
Does my research software deserve a GUI?
The first thing you will need to decide is if your software - a existing one or a project you are starting from scratch - deserves a GUI at all. And to do that, it is important to know what kind of software are you working with.
We are going to divide research software into four categories: libraries, frameworks, command line interface (CLI) apps and GUI apps. As is common when classifying things, boundaries between categories are not really that sharp and there will be software that does not fit into any of them, but it is useful to start our discussion.
- Libraries are toolboxes meant to be used by other software. They often contain functions to perform mathematical operations, data manipulation or exploiting specific hardware (e.g. drivers), among others. A few examples of libraries in this category would be the Python packages Numpy, xarray, SymPy or CuPy. Using libraries always requires writing some code.
- Frameworks are tightly coupled with some specific area of knowledge. They bring to the table a collection of tools useful to solve real-life problems in that area, e.g. optimising the performance of solar cells (Solcore), aligning molecular sequences (Biopython) or modelling the charge/discharge cycles of batteries (PyBaMM). Normally, not only do they contain code but also domain-specific data like universal constants, properties of materials, etc. Even though some coding is necessary to use them, often this consist on relatively simple scripts, piping some input data into the relevant high level functions and then collecting the results for plotting. Some parts could easily be converted into standalone CLI applications.
- CLI apps tend to be either facilitators of research, like Git or Docker, or tools designed to run unsupervised in high performance computers (HPC), like LAMMPS or GROMACS, but pretty much any executable tool used in research that does not have a GUI falls into this category. Options to control what these tools do are provided as arguments as well as input and configuration files. Using these apps does not require any experience in coding but some familiarity using the terminal.
- GUI apps The whole point of these apps is to provide a graphical interface to the user. Without it, their business logic cannot be exploited or simply does not exist. Most web apps fall into this category (Dandeliion), as well as integrated development environments (VS Code) and reference managers (Zotero), among others. They do not require any extra knowledge to use them beyond knowing how to use the application itself.
 Categories of research software
Categories of research software
Of the above categories, libraries cannot benefit from a GUI because they are too low level for that, and GUI apps are, by definition, GUI oriented and so they will always have one.
Now, frameworks and CLI apps could indeed use a graphical interface to more easily exploit some of their functionality. In the case of frameworks, a GUI will remove the need to have any kind of coding skills to use the application, reducing the barrier for its adoption. And in both cases, a GUI could make it more explicit to the user and easier to change the input options and the outputs generated by the software. In the case of apps for HPC, a GUI will not be that useful during the execution of the computationally intensive task, but could be helpful for setting up the calculation and for visualising and manipulating the outputs.
If your research software falls into any of these two categories (frameworks and CLI apps), keep reading because now, deciding if adding a GUI is worthwhile depends on who your users are going to be and what comes with the decision of having a GUI.
Pros and Cons of GUIs for Research Software
Including a GUI is a key decision to be taken as soon as possible in the creation process. You need to plan for all that it involves, the good and the bad. Some of these things, especially the bad, will need some careful thought and convincing the relevant people in charge that the effort is worthwhile.
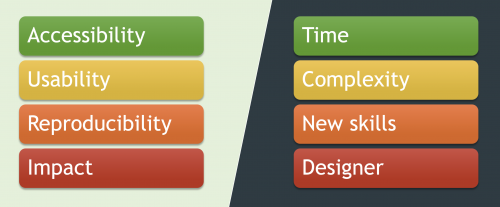 Summary of pros and cons of adding a GUI to research software
Summary of pros and cons of adding a GUI to research software
The bright side of implementing a GUI
1. Accessibility
This is probably the most important benefit of having a GUI. It is the same thing that enabled the growth of computers back in the 80s: the ability to reach anyone, even those without technical expertise.
- A GUI separates user from developer. Even if both are the same person - the approach to the software will be different and so should be the features or interface.
- A GUI can account for users’ needs, such as having a disability or speaking a different language.
- No end-user knowledge of programming or interacting with the terminal is required, allowing non-coders, non-experts in that field and even students/children (if relevant for that software) to use it.
2. Usability
Usability refers, as you can imagine, to how easy it is for a user to perform a certain task with the software, the first time and subsequently. It has several components nicely summarised in this article from the Nielsen Norman Group, but it is worth highlighting the following:
- Learnability: A GUI reduces the learning curve to start using the software and the time it takes to become proficient, especially if some standard practices of GUI design are used.
- Efficiency: Once learnt, the user can focus on getting results fasts, easily providing the research inputs and analysing the outputs, and not on technical details on how to achieve that.
- Memorability: The visual dimension makes it easier to remember how to use the tool after a break. Like muscle memory when playing a musical instrument or driving a car, it might get rusty if not used, but it makes it very easy to get up to speed again.
3. Reproducibility
A well-designed GUI could also improve the reproducibility of the results.
- By restricting the accessible functionality, providing only with the options that can be used at any given time to the user and disabling or hiding all the others, there is less scope for misusing the software.
- Validation checks in the input field provide immediate feedback on the suitability of the input parameters, and potentially corrected values.
- Input values are explicit and visually accessible, populating the relevant fields in the GUI.
However, in this aspect a GUI is a double-edge sword if it is not correctly designed. Contrary to sharing a piece of code, an input file or even a whole container with the exact environment in which to reproduce your results, in software with a GUI it is much more difficult to exactly reproduce the environment and steps necessary to get there.
4. Impact
This one is probably the most underestimated of the benefits of having a GUI. All of the reasons above have one consequence: they increase the user base for the software, and this has several implications.
- More users means more people providing feedback on usability, errors and new functionality that could be useful to add in the future and that, ultimately, will make the software better.
- The larger the user base, the more scope there is for establishing new collaborations with other research groups or industrial partners, increasing the visibility of the researchers behind the software and their institution.
- Today's users are tomorrow's developers. In the case of open source software, all these users are an excellent pool of new contributors.
- Increases citations, if the software is citable and users are encouraged to do so.
- Increases the reputation of the RSE(s) developing it, if that is the case and they receive appropriate credit in the software and the relevant publications.
Now, with great impact comes a great responsibility. Users will ask you for support and will expect an answer in a sensible timeframe, especially if it is a bug. Also, the tool will need to adapt to new OS versions and new platforms if it is to survive. In other words, it will need to be sustainable. You must be ready to face those challenges or risk the above positive impact turning against you.