Mentorship programme: Transforming qPCR data into meaningful plots for DSF analysis using Python
Mentorship programme: Transforming qPCR data into meaningful plots for DSF analysis using Python
Mentorship programme: Transforming qPCR data into meaningful plots for DSF analysis using Python
 By Konstantinos Drousiotis.
By Konstantinos Drousiotis.
This blog post reflects on our Learning to Code mentorship programme as part of a Research Software Camp.
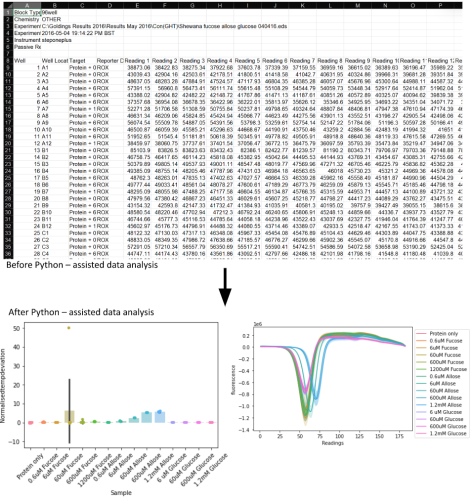
Efficient management and analysis of large datasets is an ongoing issue for protein-ligand interaction assays. Differential Scanning Fluorimetry (DSF) is a rapid and inexpensive technique for preliminary analysis of protein-ligand interactions. The technique relies on the use of dyes that bind the protein as they unfold. This experiment is also known as a Protein Thermal Shift Assay, because shifts in the melting temperature can be measured upon the addition of stabilising or destabilising binding partners. The available kits advise the scientist to perform the experiment in real-time PCR machines, even though these are not equipped with the code required to automatically perform the data analysis following export. Given the workload of most wet-lab scientists, it is a laboursome procedure to manually process the data in Excel spreadsheets.
During the duration of the Learning to Code mentorship programme, we attempted to automate the data analysis process and provide the user with plots that analyse the melting temperature of proteins in the presence and absence of the ligands of interest.
Learning to code mentorship programme
The Research Software Camp Learning to Code programme offered by the Software Sustainability Institute provides the opportunity to scientists to receive one-to-one mentorship for the duration of 12 weeks. I was paired with Dr. Dezerae Cox, a Research Fellow at the University of Cambridge who works to uncover the fundamental drivers of neurodegenerative diseases. Dezerae offered her expertise, knowledge and enthusiasm in Python to assist in automating the process described above. Our main target was for me to acquire specialised knowledge in analysing biological data, following a general course on data analytics I attended at the end of 2021. Through a structure of regular meetings and tutorial-based resources we worked through DSF data which introduced me to Python data analysis specifically for protein-ligand interactions.
My experience with Python prior to this was limited, therefore this programme has provided essential resources to develop further while being productive outside research. Even though Python is generally considered a relatively easy programming language to learn, it takes time to master and this course was definitely a stepping stone for introducing coding in my daily data-analysis routine. Working through Python tutorials as well as attending our weekly meetings, I realised that the Virtual Studio (VS) provides a very user-friendly interface which allows quick integration of libraries using commands. It was exciting to work with pandas and matplotlib, while being able to automatically back-up all work progress in Github.
We started our project by incorporating the relevant Excel data frames into VS and attempted to reformulate their structure, making it easier to manipulate. To achieve this, we used pandas which were also employed in calculating the minima from each sample, averaging and subtracting from control. Following data manipulation, we created line and barplots using matplotlib and seaborn libraries. This was a completely different process compared to manually analysing the data and improving the aesthetics using Graphpad which was exciting for me to experience.
The course has provided me with the opportunity to apply Python in data analysis for biological data. This was achievable by being consistent and having a schedule of tangible aims for each week. It required a good level of organisation but also Dezerae’s expertise and patience! I strongly recommend signing up for such programmes as they are a great way to get you going with some software programming skills.