
Machine learning (ML) and artificial intelligence (AI) have quickly become part of the modern research toolkit, changing how scientific software is built and maintained. As their use grows, it is important to maintain fundamental principles of research software—reusability, reproducibility, and transparency. This guide introduces the paradigm shift from rule-based to experiment-focused software and outlines practices and tools for designing research software to support ML tasks.
Deterministic Foundations of Research Software
In traditional research software, computational methods transform data into results, from imaging and data analysis to large-scale scientific simulation. These programs are typically deterministic, meaning the same input always produces the same output. The developer explicitly defines the transformation function (for example, y=f(x)) and, because the behaviour is fully determined by the program logic, the results are repeatable, verifiable, and transparent. These are properties that standard quality assurance practices, such as unit testing, rely on.
ML departs from this paradigm. Instead of the developer manually defining the transformation function during training, the ML model approximates f(x) by estimating its parameters from example input-output pairs (x,y). The trained model is therefore shaped by the learning algorithm, the training and validation data, the optimisation process, and configuration choices.
The accompanying figure contrasts a deterministic system with three independently trained models, each receiving the same input but producing different outputs across training runs.
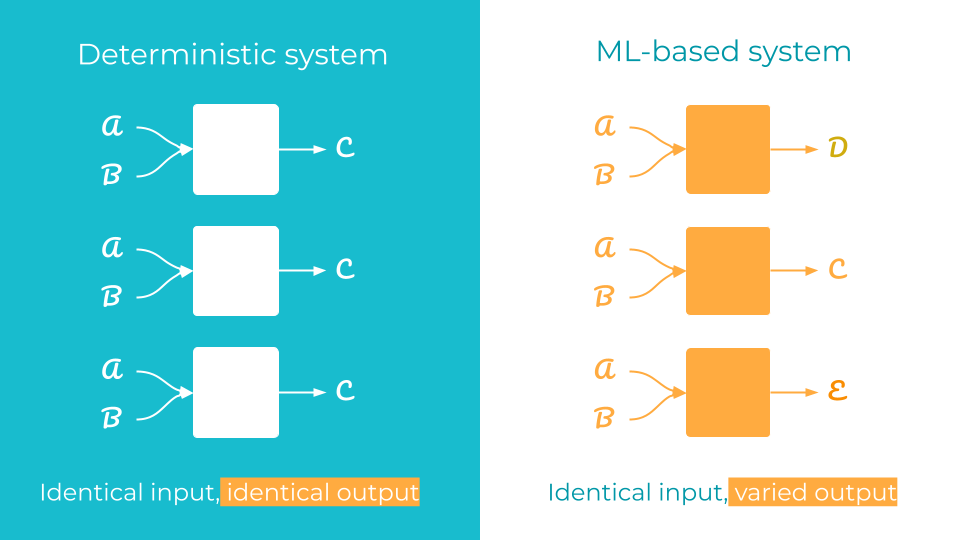
This paradigm shift affects governance and reproducibility. In deterministic systems, codebase version control is generally sufficient, since the program logic fully determines the outcome. In ML systems, the code specifies how training should proceed but does not capture the experimentation itself: the data used, the hyperparameters tried, and the random seeds of countless configurations along the way. It is entirely possible to produce a high-performing model with no reliable record of its construction. The artefact exists; the path back to it does not.
“Even perfectly versioned code cannot reveal which data |
|---|
Reproducibility, Governance, and Supporting Tools
This shift moves researchers from a script that produces a result to an experiment that produces a model. Reproducibility now relies on capturing all conditions under which training occurred.
Fortunately, established ML Engineering and MLOps practices offer ways to manage this complexity. MLOps extends software engineering principles to ML, focusing on automation, reproducibility, and governance throughout the entire ML model lifecycle. Standard workflows typically feature dataset versioning, training pipelines, experiment tracking, model registries, continuous integration and deployment, production monitoring, and environment reproducibility. Collectively, these practices reduce ad hoc work, making the experimental record a first-class artefact alongside the model itself. In practice, this means being deliberate about three key areas, with supporting tools discussed at the end of this section:
The first is data. Reliable ML systems depend on clear data provenance and reproducible preprocessing. Best practices include capturing raw data hashes, version-controlling data preprocessing pipelines, and validating that incoming data conforms to expected schemas and distributions. Generating distinct training, validation, and test data is essential to prevent data leakage, with the test set only used for final evaluation. The dataset should be tagged with its version. Any data augmentation during training must be tracked and repeatable (applied offline and saved, or with a chosen random seed). Without these safeguards, a model's provenance becomes opaque: even perfectly versioned code cannot reveal which data actually shaped the model.
The second is the training process itself. Model behaviour is highly sensitive to choices such as architecture, optimisation strategy, random initialisation, and evaluation metrics. These sources of variability must be systematically captured through experiment tracking. Without such tracking, a model may be impossible to reproduce or explain, and subsequent runs may behave unpredictably.
Third is model evaluation. Offline metrics alone are insufficient; models should be validated against datasets that were previously excluded from the training process. Take care not to exhaust this resource through model evaluation. When data arrives continuously, production monitoring provides an additional source of out-of-sample evaluation and is essential for detecting data drift and model degradation over time.
Several tools support these directly, spanning orchestration, versioning, tracking, and model management:
- Pipeline orchestration tools, such as Prefect, manage and schedule workflows, while purpose-built ML pipeline frameworks (for example, ZenML) provide abstractions tailored to ML workloads.
- Data versioning tools, such as Data Version Control (DVC), extend version control to datasets and data preprocessing steps, linking them directly to model outputs. This helps ensure experiments can be reliably reproduced as datasets evolve over time.
- Experiment tracking platforms, such as MLflow and Weights & Biases, record configurations, hyperparameters, metrics, and artefacts across training runs, enabling results to be traced.
- Model registries and sharing platforms, such as Hugging Face, serve as structured repositories for storing trained models with metadata, documentation, and evaluation results. This supports repeatability, reproducibility, and model reuse within the research community.
Combined, they allow ML systems to be developed with the same rigour and traceability expected of any other piece of scientific software.
Further reading
Chip Huyen, Designing Machine Learning Systems (O'Reilly, 2022)
Acknowledgements
This guide was written by Paul J. Wright and reviewed by Yo Yehudi.
- Paul J. Wright's ORCID: https://orcid.org/0000-0001-9021-611X
- Yo Yehudi's ORCID: https://orcid.org/0000-0003-2705-1724