Workflow systems for science: programming in the large
Workflow systems for science: programming in the large
By Daniel S. Katz, Assistant Director for Scientific Software and Applications at the National Center for Supercomputing Applications, University of Illinois Urbana-Champaign.
This article is part of our series: A day in the software life, in which we will be asking researchers from all disciplines to discuss the tools that make their research possible.
A large amount of today’s computational and data science involves combining the execution of many tasks that each run a model or transform data, to build up a multi-component model or a multi-stage data transformation. Most researchers initially do this manually, and then (if they have any programming experience) eventually move to using shell scripts when the manual process gets too painful. However, shell scripts tend to limit the work to single resources, as they don’t really work well with parallel computing.
An alternative method is to use a system that I’ve been involved in developing: the Swift Parallel Scripting Language. (Note that there’s no relation here to Apple’s Swift, other than that they reused our name.) Swift provides an implicitly parallel and deterministic programming model, which applies external applications to data collections using a functional style that abstracts and simplifies distributed parallel execution. Swift addresses many complications commonly associated with parallel and distributed computing, including scale, distribution, complex dependencies, scheduling, heterogeneity and flexibility, fault tolerance, debugging, and performance.
A Swift user today writes a high-level script with C-like syntax that expresses a set of operations, which are often external executables or simple functions, in terms of their inputs and outputs. Swift examines the script, and runs any task that has all its inputs available, using as many resources as are available, whether laptops cores, HPC nodes, or cloud nodes. Once these tasks run and produce outputs, additional tasks that use those outputs as their inputs can be run, and so on, until all tasks have run. We refer to Swift as “programming in the large”, since this is really “programming the orchestration of application programs.”
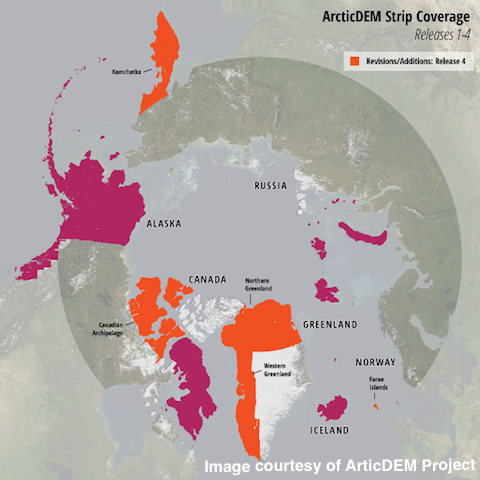
One group using Swift is the ArcticDEM project at the Polar Geospatial Center at the University of Minnesota, with partners from Ohio State University (OSU) and University of Colorado - Boulder. The project’s goal is to “produce a high-resolution, high-quality, digital surface model (DSM) of the Arctic using optical stereo imagery, high-performance computing, and open source photogrammetry software.” In order to do this, it has to process a stream of satellite images and build them into Digital Elevation Models (DEM) strips (as imaged by orbiting satellites) and DEM mosaics (assemblages of multiple strips that cover larger areas.)
This type of processing is different from how HPC systems are usually configured. For example, sites typically impose policies on batch job schedulers to allow a relatively small numbers of large jobs to run, and will only run an even smaller number of jobs for a given user at once to avoid scheduler overhead and encourage scaling of workloads. The ArcticDEM project needed a way to bundle over 500,000 single-node tasks into a smaller set of 100- to 1000-node jobs. Swift manages the grouping of the ArcticDEM tasks, and also handles the queue of unfinished tasks, adding new tasks into the pool of running jobs as tasks finish. As a result, the ArcticDEM project’s jobs are large enough to avoid burdening the HPC scheduler and still small enough to fit in otherwise unused nodes, increasing the utilisation of the machine. Most importantly, Swift enabled the ArcticDEM project to use over 18 million node hours compute time on Blue Waters since 2016. To date, the project has produced four data releases towards its goal of complete Arctic coverage.
While Swift’s parallel semantics are powerful and productive, learning a new language can be a burden. To remove this barrier, we have developed a prototype Python module, Parsl, to provide Swift’s functionality as a “parallel scripting library”. The module enables a programmer to annotate Python scripts so that they behave like distributed parallel workflows. Parsl can run both moderately-large file-passing tasks (on the order of a minute or more), which are well-suited to high-throughput distributed systems such as clouds and grids, as well as in-memory workflows with shorter tasks (down to fractions of a second), better suited to high-performance cluster and supercomputer systems. It provides a unified solution for both of these regimes by providing interfaces to both dynamic resource managers and a highly scalable MPI-based workflow runtime system. A preliminary tutorial for Parsl is available here. (Click on First-Tutorial-Start-Here.ipynb to start it. Use the run cell button [![]() ] to step through the cells. After the cell that starts with “# Print the results”, you will have a wait a few seconds for the work to be done before the results print.)
] to step through the cells. After the cell that starts with “# Print the results”, you will have a wait a few seconds for the work to be done before the results print.)
Acknowledgements
The Swift team, led by Michael Wilde at Argonne National Laboratory and the University of Chicago, with Parsl developed by Yadu Nand at the University of Chicago; the ArcticDEM team led by Paul Morin with software lead Claire C. Porter, both at the Polar Geospatial Center, University of Minnesota; and the Blue Waters Science and Engineering Application Support group at NCSA, led by Greg Bauer with Blue Waters Point of Contact Galen Arnold.
Image: ArcticDEM Strip Coverage (Release 4). Strip DEM files correspond to the overlapping area of the input stereopair image swaths as they are collected by DigitalGlobe’s constellation of polar-orbiting satellites.