Below-the-line conversations: A computer-facilitated case study of Guardian reader comments
Below-the-line conversations: A computer-facilitated case study of Guardian reader comments
Below-the-line conversations: A computer-facilitated case study of Guardian reader comments
 Photo by Kelly Sikkema on Unsplash
Photo by Kelly Sikkema on UnsplashBy Yenn Lee, SOAS University of London, @yawningtree.
This blog post is part of the series of resources on learning to code, hosted as part of the Research Software Camp: Beyond the Spreadsheet.
I volunteered to participate in this year’s Research Software Camp, “Beyond the Spreadsheet”, by the Software Sustainability Institute (SSI). This short piece recounts my experience of the programme over the past two months, in the hope to share what I have found and learnt along the way.
I am a digital sociologist with a focus in the Asia–Pacific region. In my current position as a Senior Lecturer in Research Methodology and Deputy Director of the Doctoral School at SOAS University of London, my main responsibility is to teach research methods and skills to PhD students across the arts, humanities, and social sciences. At the confluence of my research and teaching is the question of whether, how, and to what extent we need to reconfigure research methods when studying a digitally mediated social phenomenon. Digital ethnography is where my specialism lies, but I have been on various collaborative projects that are more quantitatively oriented and based on ‘big data’, and I have been intending to expand my own methodological repertoire and become more hands-on with coding myself. I dipped in and out of some self-help resources previously, but like with learning any other languages, I felt I needed a little more ‘scaffolding’ for an effective and committed start. To be frank, I was not familiar with the Research Software Camps prior to this occasion, but after a briefing meeting with Selina Aragon, the SSI Communications Lead and Research Software Camp Chair, I was glad I signed up.
The project
At the beginning of September 2021, I was assigned a mentor, Mario Antonioletti, and together we set up a mini project with the same title as this blog post. The project was born purely out of curiosity. The Guardian used to run, from February 2014 to May 2019, a series of articles called “Academics Anonymous”, where unnamed authors vented their concerns and frustrations about the higher education sector, where they were apparently insiders. Articles in the series were likely to pertain to sensitive topics, such as job precarity, workplace bullying and discrimination, and research malpractice, to name but a few. I did not read them all when the series was running, but I was aware that those articles would often make the rounds and triggered strong responses from readers in the ‘below the line’ comment sections as well as on Twitter and Facebook.
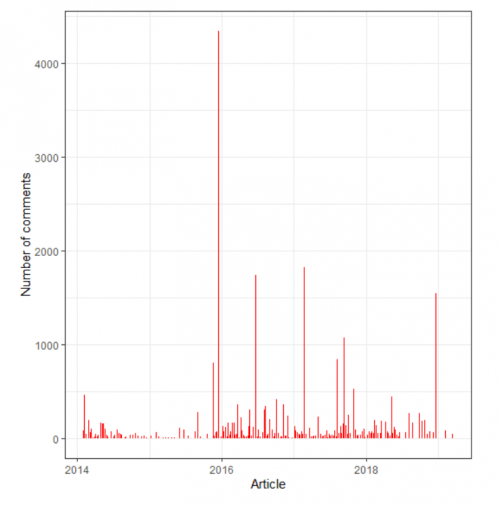
One article in particular, “My students have paid £9,000 and now they think they own me” (18 December 2015), received 4,343 comments from readers—far higher than the usual level of engagement that the series ever saw. I was intrigued what about this particular piece set it apart from the rest, and I thought I would take advantage of this training opportunity to explore various techniques to analyse online comments and reviews. Mario and I chose to work in R, as I had some prior exposure to it, albeit minimal, unlike Python or other computer languages.
We created a GitHub repository for the project and met every Thursday for 9 weeks virtually to discuss our progress. With the help of The Guardian’s Open API and its Discussion API, we retrieved all articles in the series—there were 187 of them in total—and their metadata including the counts of comments that they received respectively. This enabled us to confirm that our chosen article was indeed a distinct outlier, as illustrated in the graph below. Scraping the reader comments was not quite so straightforward, as these were JavaScript-generated, and took us longer than we initially assumed. Nevertheless, after collecting all 187 articles in the series and all 4,343 comments posted to the article of our choice, we have been attempting a topic analysis of the articles, a sentiment analysis of the articles, and a network visualisation of the comment exchanges. The exploration is still ongoing, and I am intending to write up a fuller piece once the analysis is complete.
My thoughts on the Learning to Code programme
In the meantime, here are a few personal reflections. First of all, I find this ‘project-based mentoring’ approach incredibly helpful. I must admit that it was a bit of a dive in at the deep end for a beginner like myself, but Mario was generous with his time and guidance, and I could not have asked for a better mentor.
Second, I realised as soon as our project kicked off that my level of R was too elementary for me to write codes more independently. I was rather at a stage of language learning where one observes and mirrors a more fluent speaker. This must have been demanding for the mentor, and I thank him for now being able to navigate further resources with more confidence and ease than before.
Time, or lack of it, was another challenge, since September and October are the busiest months in the academic calendar. I was not able to dedicate as much time as I wished to. I am glad that we at least stuck to our weekly meetings regardless, which helped to maintain the momentum of the project.
Most importantly, the programme has given me an opportunity to discuss with a fellow research software enthusiast many interesting methodological questions. For example, when your dataset is too large for you to comb through manually and hence you rely on an R package to distill it into bags of (what it deems to be) salient words, how do you make an interpretative leap from there? Or when you intuitively know a text is sarcastic but an established R package tells you that the text conveys ‘positive’ sentiments, what do you do to reconcile that? These are big questions to ponder, and it is this room for reflection that I have enjoyed and appreciated most.
I know I will be championing the Research Software Camps and I hope I get to participate in other SSI initiatives in the future.