Alessandro Felder and Niko Sirmpilatze are both 2025 SSI Fellows and Senior Research Software Engineers at the Sainsbury Wellcome Centre, a neuroscience research institute affiliated with UCL in London. Alessandro is a core developer of the BrainGlobe Initiative, an open-source suite of tools for processing and visualising brain microscopy data. Niko leads movement, an open-source Python package for analysing animal body movements from video.
Overview
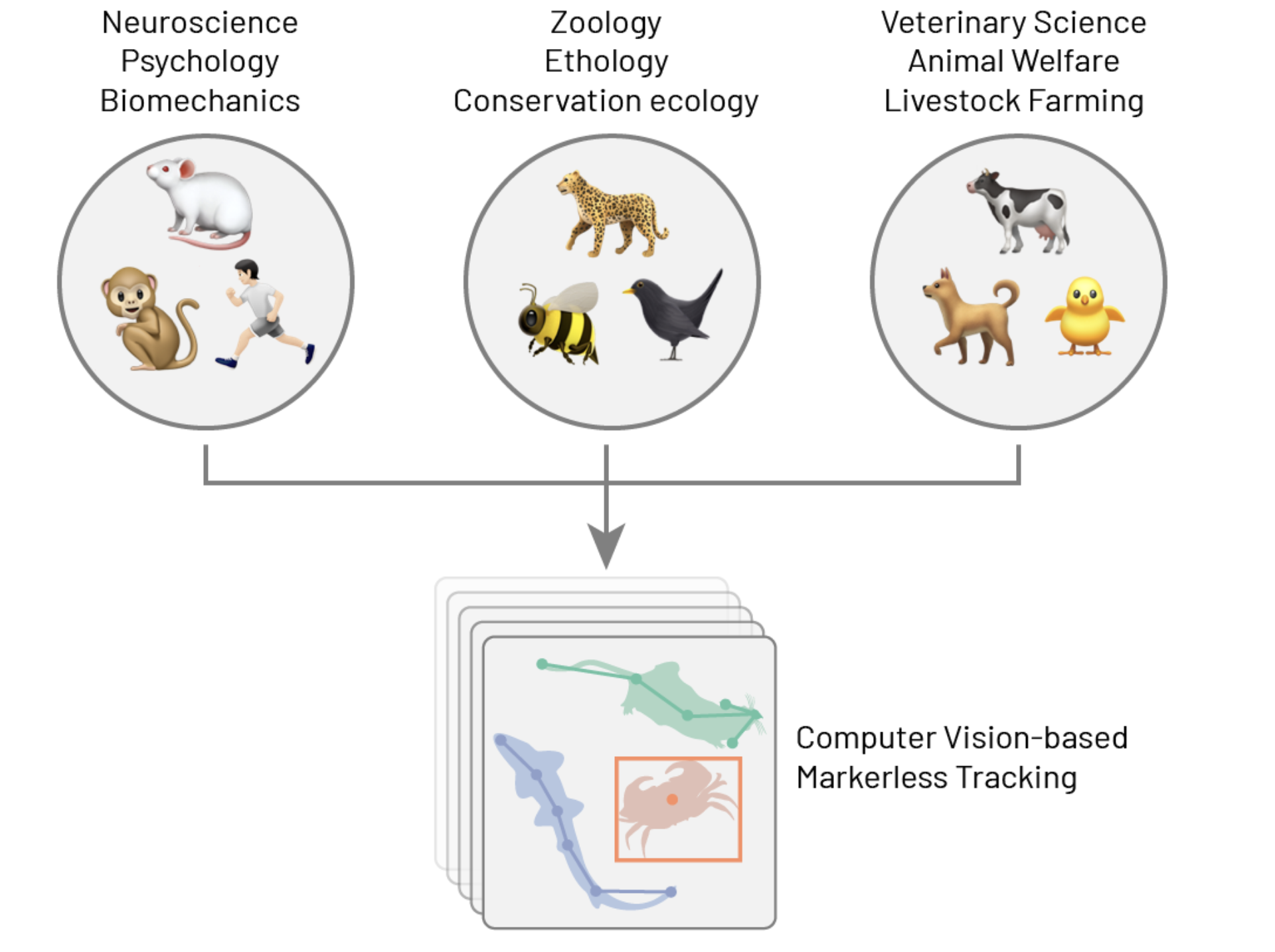
In August 2025, we co-organised the Neuroinformatics Unit Open Software Week (OSW) a five-day event that brought together 44 attendees from 12 countries across four continents to learn open-source approaches for handling large imaging datasets, processing whole-brain microscopy data, and analysing behavioural videos. OSW emerged by combining our SSI Fellowship plans into a single, larger initiative.
Across the week, 13 speakers delivered seven sessions, grouped into three main tracks supported by four shared satellite events:
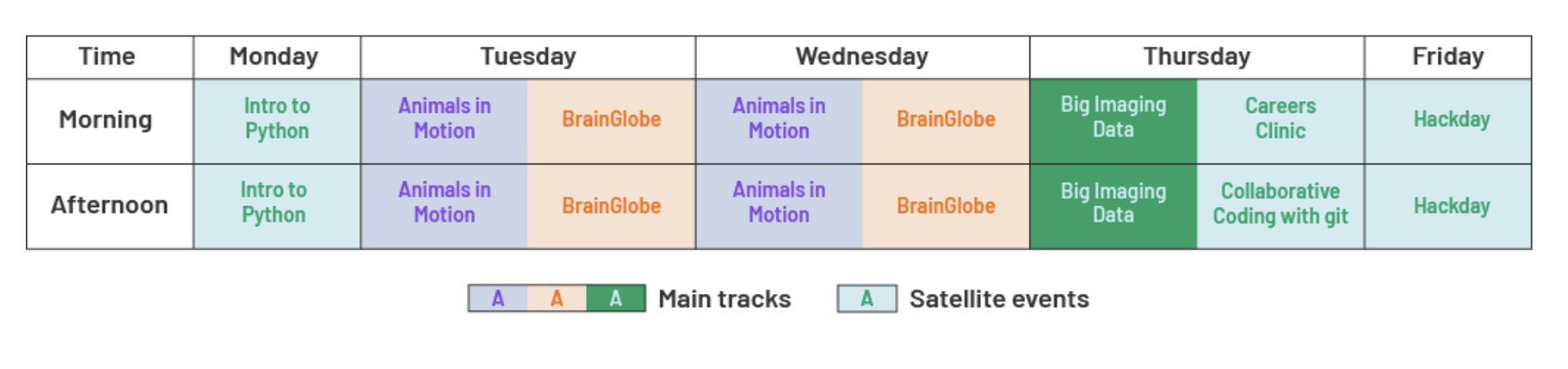
Schedule of the Neuroinformatics Unit Open Software Week.
Main tracks
- Animals in Motion focused on open-source tools for tracking and analysing animal motion from video.
- BrainGlobe consisted of a hands-on introduction to open-source tools to process, analyse and visualise brain microscopy data.
- Big Imaging Data featured introductory technical tutorials and a community session around big imaging data formats and libraries.
Animals in Motion was led by Niko, while the other two tracks were led by Alessandro.
Shared satellite events
- Introduction to Python — optional one-day refresher for participants wanting to strengthen their programming foundations ahead of the technical sessions.
- Careers Clinic — a panel discussion with five Research Technology Professionals from life sciences, highlighting diverse career routes and opportunities.
- Collaborative Coding with Git — practical guidance on version control and contributing to projects on GitHub.
- Hackday — a dedicated day for participants to collaborate on small projects, drawing inspiration from the SSI’s Collaborations Workshops.
The programme was supplemented by a series of diverse social events in the evenings, including a walk in the Regents Park, an Irish folk music jam session, a neuroscience-themed pub quiz, and a creative live-coding evening.
In the two companion blog posts, we describe the individual training tracks we led and how they helped advance our respective Fellowship goals.
In this post, we reflect on the experience of joining forces to achieve something more ambitious than either of us originally envisioned. We share how the event came together, the synergies that shaped it, and our plans for the future.
Synergistic fellowships
Open Software Week wasn’t part of our original plan. We had each proposed independent Fellowship projects and were simply lucky that both were funded in the same cohort. The idea to combine them came to us later. It made sense — we work side by side at the same institute and had already planned to use the same spaces for our respective events. We expected that we could combine some parts of our events, such as the hackday, and share the logistical and administrative burden. To our surprise, joining forces came with other unforeseen benefits, too!
We didn't expect how much working together would help us when we needed someone to bounce ideas off, or someone to hold us accountable for getting things done (including writing this blog post!).
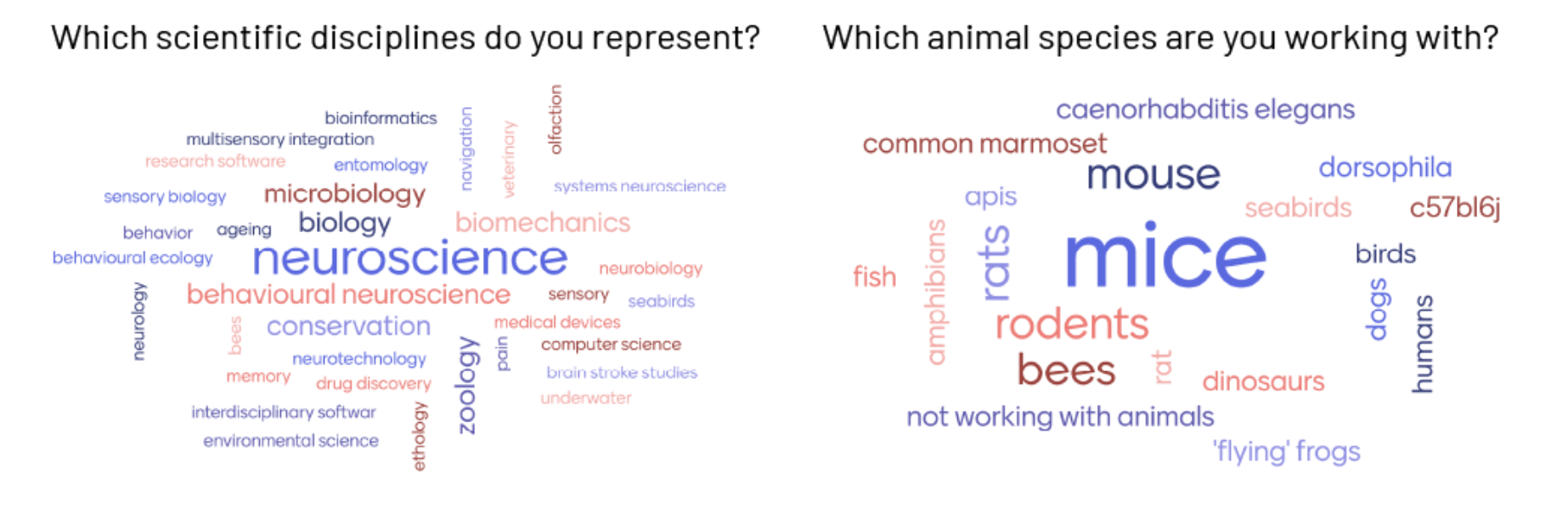
We also benefited from each others' and our line manager Adam Tyson's perspective as we reviewed an overwhelming amount (~120) of high-quality applications. We were limited to 50 participants - the maximum number we could teach hands-on in our space. It was a lot easier to make tough decisions together. It helped that Niko wasn't as emotionally close to Alessandro's plans, and vice-versa. Adam could tie-break and keep a higher-level perspective.
Making our fellowships into a larger event with existing seed-funding allowed Adam to secure additional sponsorship for OSW. We got small grants from the Society for Research Software Engineering and AIBIO-UK, as well as support from our host institute. The Sainsbury Wellcome Centre provided funding for OSW in addition to their already generous in-kind contribution of administrative support and provision of teaching rooms. This enabled us to provide catering throughout the week, not charge registration fees and support eight participants with accommodation and travel costs.
Attending tracks on different topics did not prevent our participants from making friends during the shared breaks and social events. The boundaries between our events were fluid and we were happy to see many engaging interactions: a participant switched tracks at the last minute, an Animals in Motion attendee helped with BrainGlobe problems during the hackday, and a few participants took time out of the Big Imaging Data event to attend the Careers Clinic.
Although OSW grew out of our SSI Fellowship initiatives, it was quickly and enthusiastically adopted by our fellow research software engineers in the Neuroinformatics Unit. A final positive outcome was that organising and leading OSW (it was pretty intense, to be honest!) brought us closer together as a team. The end of the week found us having tea and biscuits together, exchanging stories and cooling down from all the excitement.
What made Open Software Week a success
OSW was rewarding and worthwhile for us organisers, and we hoped that the participants would share this experience. Gratifyingly we received overwhelmingly positive feedback; we've included some anonymous excerpts below.
Sparked a bit of a eureka moment after months of agonising over how to analyse my data!
My whole PhD feels doable now!
The heterogeneity of the attendees was truly enriching.
Atmosphere was very friendly and down to earth.
The communication and offers of help were incredibly kind and respectful. I felt uninhibited to ask questions, which I don't take for granted!
It was incredibly valuable to learn directly from the developers and share the space with researchers from across the field.
I thought the motivations behind the week and the organising team were eye-opening as to how to make a career supporting research and doing this type of work. I didn't expect to feel as welcomed and motivated to keep going in this field…
Moreover, we had little to no decline in participation as the week progressed. Attendees, including the locals, kept showing up for all the days they'd signed up for. Many of them remain engaged on our public discussion forums and some have already contributed multiple times to our open-source tools. One of our participants, Marco Dalla Vecchia, wrote a first-hand account of his experience, which you can read on the Neuroinformatics Unit website.
We have been reflecting on what made this event such a success.
One factor that stood out was our model of combining domain-specific data analysis training with general good research and software practices. Because participants were already motivated to learn skills they could immediately apply in their own work, they were more engaged and receptive to topics that can otherwise seem dry, such as version control or introductory Python. We think this integrated approach may be more effective than teaching software skills in isolation. Our selection process also reinforced this, as we prioritised applicants who were likely to make immediate use of the tools and methods covered.
We also made a concerted effort to create a welcoming and informal atmosphere, using techniques from SSI Collaborations Workshops and other communities with a similar ethos—like Brainhack. Each day started with a welcome session, where everyone was reminded to follow the Code of Conduct, be collaborative and respectful, make friends and have fun. We encouraged participants to follow the Pacman rule and tried to lead by example on that. We also made sure to include unconference-type sessions with participant-led co-working activities and provided an online platform for people to chat during the event.
Looking ahead
We plan to build on the success of OSW by growing it into an annual summer school. Next year's event is scheduled for August 17th-28th 2026 and registration opened on December 1st 2025.
We aim to expand the programme to two weeks. This will allow us to introduce a dedicated additional track on electrophysiological data, an important neuroscientific modality that was missing in 2025. The 2026 event will also provide more opportunities for participants to present their work and have more time for collaboration.
To ensure long-term sustainability, we will shift to a mixed funding model that combines sponsorship with registration fees, while continuing to offer travel support for participants from under-resourced institutions and countries.
We are excited to host our next cohort in London next summer!
Acknowledgments
Looking back, OSW feels like the most impactful initiative we have undertaken so far. Experiencing how our efforts helped connect researchers across disciplines and career stages was deeply fulfilling. We are grateful to everyone who helped transform our initial fellowship ideas into something far greater.
We wish to thank all of our colleagues in the Neuroinformatics Unit. Shout-out to Adam, Chang Huan, Igor, Joe, Laura and Sofía, who all contributed in multiple ways, from developing and delivering training materials, to organising social activities and leading hackday projects.
OSW would not have taken place without the generous funding from the SSI, the Sainsbury Wellcome Centre, the Society for Research Software Engineering and AIBIO-UK. The finance teams at SSI and the Sainsbury Wellcome Centre also helped streamline the admin and ensured we never had to cover costs out-of-pocket. Our Events Manager Karen Fergus was instrumental in arranging room bookings and, crucially, managing travel and reimbursements for the eight stipend recipients. The food provided by the catering team received frequent praise in participant feedback, and the security team supported us with room set-up and access throughout the week.
We extend our thanks to our panelists — Mayo Faulkner, Vicki Yorke-Edwards, Laura Porta, Jonas Hartmann, and SSI Fellow Batool Almarzouq — for generously sharing their time and career insights with participants.
Finally, we appreciate the contributions of those who brought creativity and fun to our social events. Jesse Krichefski and Ryan Cini prepared questions for our pub quiz, and the creative group pastagang performed live-coded music and visuals in a collaborative jam with OSW participants.
The most important people to thank are the participants themselves, who trusted us with a week of their time, and contributed not only intellectually, but also by shaping a positive and supportive atmosphere. We are greatly enriched by our interactions with them, and we hope they were too.