
As part of our new series on Artificial Intelligence in research software, we have published a new guide: Getting Started with ML and AI in Research Software, written by Paul J. Wright and reviewed by Yo Yehudi.
Bookmark this page
Bookmarked

Getting Started with ML and AI in Research Software
Estimated read time: 5 min
Sections in this article
Getting Started with ML and AI in Research Software
Machine learning (ML) and artificial intelligence (AI) have quickly become part of the modern research toolkit, changing how scientific software is built and maintained. As their use grows, it is important to maintain fundamental principles of research software—reusability, reproducibility, and transparency. This guide introduces the paradigm shift from rule-based to experiment-focused software and outlines practices and tools for designing research software to support ML tasks.
Deterministic Foundations of Research Software
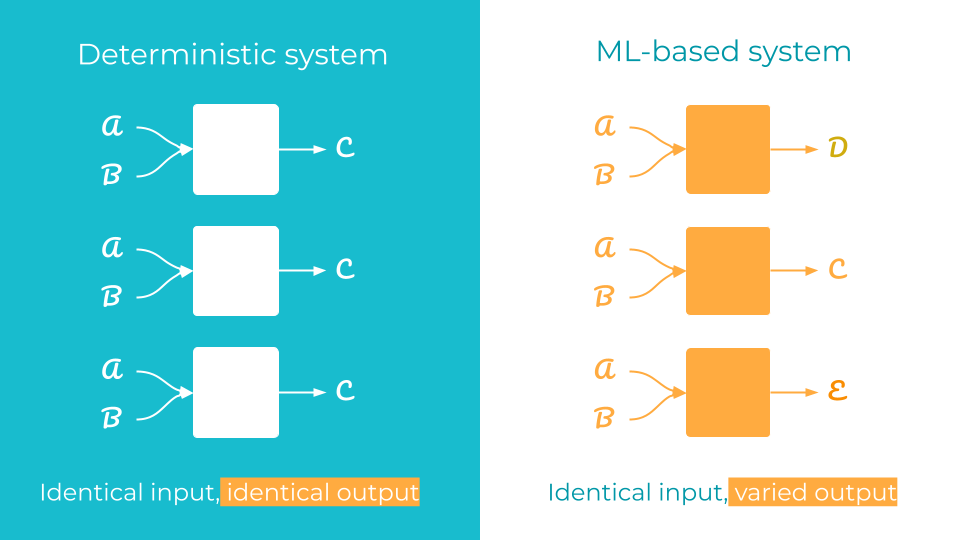
In traditional research software, computational methods transform data into results, from imaging and data analysis to large-scale scientific simulation. These programs are typically deterministic, meaning the same input always produces the same output. The developer explicitly defines the transformation function (for example, y=f(x)) and, because the behaviour is fully determined by the program logic, the results are repeatable, verifiable, and transparent. These are properties that standard quality assurance practices, such as unit testing, rely on.
ML departs from this paradigm. Instead of the developer manually defining the transformation function during training, the ML model approximates f(x) by estimating its parameters from example input-output pairs (x,y). The trained model is therefore shaped by the learning algorithm, the training and validation data, the optimisation process, and configuration choices.
The accompanying figure contrasts a deterministic system with three independently trained models, each receiving the same input but producing different outputs across training runs.
This paradigm shift affects governance and reproducibility. In deterministic systems, codebase version control is generally sufficient, since the program logic fully determines the outcome. In ML systems, the code specifies how training should proceed but does not capture the experimentation itself: the data used, the hyperparameters tried, and the random seeds of countless configurations along the way. It is entirely possible to produce a high-performing model with no reliable record of its construction. The artefact exists; the path back to it does not.
“Even perfectly versioned code cannot reveal which data |
|---|
Reproducibility, Governance, and Supporting Tools
This shift moves researchers from a script that produces a result to an experiment that produces a model. Reproducibility now relies on capturing all conditions under which training occurred.
Fortunately, established ML Engineering and MLOps practices offer ways to manage this complexity. MLOps extends software engineering principles to ML, focusing on automation, reproducibility, and governance throughout the entire ML model lifecycle. Standard workflows typically feature dataset versioning, training pipelines, experiment tracking, model registries, continuous integration and deployment, production monitoring, and environment reproducibility. Collectively, these practices reduce ad hoc work, making the experimental record a first-class artefact alongside the model itself. In practice, this means being deliberate about three key areas, with supporting tools discussed at the end of this section:
The first is data. Reliable ML systems depend on clear data provenance and reproducible preprocessing. Best practices include capturing raw data hashes, version-controlling data preprocessing pipelines, and validating that incoming data conforms to expected schemas and distributions. Generating distinct training, validation, and test data is essential to prevent data leakage, with the test set only used for final evaluation. The dataset should be tagged with its version. Any data augmentation during training must be tracked and repeatable (applied offline and saved, or with a chosen random seed). Without these safeguards, a model's provenance becomes opaque: even perfectly versioned code cannot reveal which data actually shaped the model.
The second is the training process itself. Model behaviour is highly sensitive to choices such as architecture, optimisation strategy, random initialisation, and evaluation metrics. These sources of variability must be systematically captured through experiment tracking. Without such tracking, a model may be impossible to reproduce or explain, and subsequent runs may behave unpredictably.
Third is model evaluation. Offline metrics alone are insufficient; models should be validated against datasets that were previously excluded from the training process. Take care not to exhaust this resource through model evaluation. When data arrives continuously, production monitoring provides an additional source of out-of-sample evaluation and is essential for detecting data drift and model degradation over time.
Several tools support these directly, spanning orchestration, versioning, tracking, and model management:
- Pipeline orchestration tools, such as Prefect, manage and schedule workflows, while purpose-built ML pipeline frameworks (for example, ZenML) provide abstractions tailored to ML workloads.
- Data versioning tools, such as Data Version Control (DVC), extend version control to datasets and data preprocessing steps, linking them directly to model outputs. This helps ensure experiments can be reliably reproduced as datasets evolve over time.
- Experiment tracking platforms, such as MLflow and Weights & Biases, record configurations, hyperparameters, metrics, and artefacts across training runs, enabling results to be traced.
- Model registries and sharing platforms, such as Hugging Face, serve as structured repositories for storing trained models with metadata, documentation, and evaluation results. This supports repeatability, reproducibility, and model reuse within the research community.
Combined, they allow ML systems to be developed with the same rigour and traceability expected of any other piece of scientific software.
Further reading
Chip Huyen, Designing Machine Learning Systems (O'Reilly, 2022)
Acknowledgements
This guide was written by Paul J. Wright and reviewed by Yo Yehudi.
- Paul J. Wright's ORCID: https://orcid.org/0000-0001-9021-611X
- Yo Yehudi's ORCID: https://orcid.org/0000-0003-2705-1724
Bookmark this page
Bookmarked


AI Imaginary and World Models: From Seeing to Making Worlds
The Software Sustainability Institute and Lingnan University, Hong Kong, are proud to jointly feature a webinar on AI world models. The event will take place online on Friday 17 April between 9 and 10.30 BST.
As AI transitions from processing data to generating environments, this session asks the pivotal question: What happens when AI goes beyond simulating reality and begins actively building it?
Professor Sunil Manghani will challenge our understanding of cognition itself, asking whether AI’s capacity for “world-making” suggests reality is more computable—and more finite—than we ever imagined.
Professor Harry Yang will unveil World Action Models (WAMs), a breakthrough framework that allows robots to “imagine” the physical consequences of their actions before moving, paving the way for a new generation of embodied physical intelligence. Don’t miss this opportunity to explore the philosophical implications and technical breakthroughs defining how AI moves from seeing to making worlds.
The event will be moderated by SSI Fellow Gerui Wang.
HomeNews and blogs hub
Bookmark this page
Bookmarked
Open source AI/ML guided drug discovery workshop: translating learnings from Africa to LATAM

Open source AI/ML guided drug discovery workshop: translating learnings from Africa to LATAM

Image: Hands-on session ongoing at the Facultad de Ciencias Exactas y Naturales, UBA
The Ersilia Open Source Organisation, the research non-profit I co-founded and lead since 2020, was founded with a clear objective: equip laboratories in low-resource regions with open source AI/ML tools for infectious disease research. As part of our mission, we focus on three areas of impact: i) development of AI-based research software for drug discovery, ii) research in infectious diseases, and iii) capacity strengthening in AI. On the latter, we organise workshops on the application of AI methods for drug discovery and target medicinal chemists, molecular biologists, pharmacists and bioinformaticians in regions where these diseases are endemic. Oftentimes, we group the countries we support under the controversial “global south” term. While widely used to make a distinction between westernised or global north countries (a.k.a, Europe, North America and Australia), it lumps together very different countries, and is even geographically incorrect. Most of Ersilia’s work has so far been developed in Africa. Through a series of grant-funded events, we have delivered in-person workshops in South Africa, Cameroon, Kenya, Ghana and Zambia, and our experience in other “global south” countries, including the Latin American (LATAM) region, is scarce. Therefore, we were thrilled when the opportunity appeared to co-organise a workshop in Buenos Aires, Argentina.
For a successful event, having a local host that can support the event organisation, connect with relevant experts for course contributions and continue the networking activities after the event is key. In previous workshops co-organised with the H3D Foundation we have counted with the support of the University of Cape Town, the University of Ghana or the KEMRI, respectively. In this case, the connection arose naturally thanks to the Open Life Sciences program. After completing my own OLS training, I have acted as mentor for two Argentinian-based projects, MetaDocencia (led by Dr. Nicolas Palopoli) and TidyScreen (Dr. Alfredo Quevedo; Universidad Nacional de Córdoba). Through these collaborations, we identified a common interest in open science, LATAM-focused training and particularly, AI for drug discovery. Together, we designed an event with the following goals:
- Learn how to adopt open source AI models for drug discovery
- Understand the FAIR principles for research software
- Understand and get experience in the use of Open Source AI/ML tools for cheminformatics and drug discovery: The Ersilia Model Hub, TidyScreen, AutodockBias, and others
- Establish a community network of researchers and software developers in Argentina who are interested in utilizing open-source AI/ML tools for Cheminformatics and drug discovery.
At Ersilia, we were really keen to translate our learnings from African-focused workshops to this first event in LATAM, and adapt our content and training materials for future opportunities. Unlike other courses, on this occasion we counted with a strong local community developing their own tools for drug discovery, such as TidyScreen, which was a great starting point to consolidate a shared curriculum giving relevance to not only one, but several computational approaches to drug discovery. In addition to Ersilia’s and the University of Cordoba team, the facilitators included the hosts at the University of Buenos Aires, Prof. Marcelo Martí and Prof. Adrian Turjanski.
In this post, we try to summarise the key elements that made this course a success:
- Blending keynote sessions with hands-on practice with real examples. Previously we had to limit hands-on sessions to smaller exercises or less applied to real world, due to technical and infrastructural constraints
- Linked to the above, having a computer room set up for the entirety of the course accelerated troubleshooting and allowed for previous installation, system-wide of the needed software. This is truly location-dependent and we are really thankful to the University of Buenos Aires for their support.
- Focusing on reproducibility and training materials. Ensuring that participants will be able to reproduce the course, play with the software and propose improvements or make requirements based on their needs is essential to increase tool adoption. At Ersilia we always prepare a Gitbook for the course, and TidyScreen also has abundant and clear documentation and case examples.
- Demonstrating the relevance of open source software. The best demonstration of this is the integration of the Ersilia Model Hub, our flagship AI platform, inside TidyScreen. Dr. Quevedo and his team took the lead in integrating our software into their pipeline and showcasing how collaboration can bring more and better research outcomes
- Adapting the concepts to the local research interests. As much as possible, using context-relevant examples makes the course more appealing to scientists. In this case, we focused on antibiotic-resistant infections and Chagas disease.
- Moving beyond English. While English is the predominant language in the scientific arena, we should acknowledge the limitations it poses to non-native speakers (including the Ersilia team). For example, we struggled previously in French-speaking Cameroon. Translation can be expensive and time consuming, but we fully advocate for it as much as possible. This time around, all course facilitators were Spanish-speaking, and the entirety of the course was delivered in Spanish, even though written course contents and documentation were in English.
- Allowing for in-person interactive time. While online training enables wider access, the opportunity to spend time together with students and other researchers sparks discussion and collaboration that is slower to build in online settings. However, to ensure equitable participation, we offered a hybrid course, and online participants could join in all sessions, including the hands-on.
In sum, we offered a course that blended several open-source tools for drug discovery from local (Universidad de Buenos Aires), regional (Universidad Nacional de Córdoba) and international (Ersilia) organisations, demonstrating how different research software tools can interact and complement each other. We had fifty in-person and twenty online attendees, and after the four-days course, participants left with a solid understanding of how to use the tools, guidance for implementing the learnings in their own projects and a network of contacts to expand their career opportunities and research interests, a networking that continued in the adjunct RICiFa conference. The support through the Further Development Grant from the Software Sustainability Institute (of which I am a fellow) was key to enable the participation of Ersilia facilitators in the event.
HomeNews and blogs hub
Bookmark this page
Bookmarked
UK Government AI for Science Strategy and SSI Responsible AI in RSE study group
UK Government AI for Science Strategy and SSI Responsible AI in RSE study group

Today, the UK government announced its AI for Science Strategy, setting out actions to ensure the UK’s scientific ecosystem not only adapts to, but benefits from the AI for science revolution. The strategy focuses on developing a data landscape that facilitates transformative research, ensuring researchers have access to large-scale compute, building interdisciplinary research communities, and capitalising on rapid advances in autonomous labs and both general-purpose and specialist AI tools.
Bookmark this page
Bookmarked



Is AI After My Job? Navigating the Future of Research Software Engineering
| This blog is part of the Collaborations Workshop 2025 Speed Blog Series. Join in and have a go at speed blogging at Collaborations Workshop 2026. |
Introduction
The use of GenAI tools has become one of the most polarising topics in technology today, and the Research Software Engineering (RSE) community is no exception. In many RSE teams, there's a notable divide: some embrace them enthusiastically, while others maintain their distance, viewing LLM-based AI as overhyped, unreliable, unethical, or fundamentally threatening to their profession. This reluctance and scepticism may be particularly pronounced among senior developers and those with extensive experience. While many RSEs have experimented with basic tools like GitHub Copilot, relatively few have fully integrated advanced AI coding assistants into their daily workflows, potentially missing out on significant productivity improvements that early adopters consistently report.
At the recent Collaborations Workshop 2025, our discussion group tackled various concerns about the use of AI tools (generative AI, large language models, and similar AI tools) in research software development. Throughout this text, 'AI' refers to these generative AI technologies. Two major concerns were central in current RSE experiences: first is the concern about whether AI will make RSEs redundant. Second is the question of reliability and dependency: when using AI tools, how do we know when we're being "driven into a river"? This metaphor, inspired by over-reliance on GPS navigation [26], captures the risk of becoming too dependent on AI assistance such that we lose the ability to recognise when it is leading us astray.
What emerged was a clear message: while fears about AI are valid, choosing not to engage isn't a viable option. Those who don't engage with AI tools may find themselves at a disadvantage, while those who master them may enhance their unique value as RSEs. Training in AI literacy, using existing best development practices, development of critical evaluation skills, as well as establishment of community standards are needed to harness AI's power while capitalising on the domain and research expertise that defines excellent research software engineering.
The AI Dilemma: Promise and Peril
The Concerns Are Real
The anxiety around AI isn't unfounded. RSEs are raising legitimate concerns about:
Deskilling: Like GPS navigation that can leave drivers unable to read maps, AI coding assistants risk creating what some call "vibe coding" - development based on feel rather than deep understanding. The experience of becoming dependent on AI - and, as a consequence, losing or never developing skills - varies dramatically across career stages: junior developers may never develop fundamental coding skills, while senior engineers might find some of their hard-won capabilities gradually atrophying through disuse.
Quality, Bias, and Technical Debt: AI-generated code often looks polished but can introduce subtle or even gross errors, create unexplainable logic, and fail in unexpected ways. Debugging these issues can be particularly challenging because AI-generated code may implement logic that seems reasonable on the surface, but does not correspond to the way humans would normally code. Moreover, the "computer always says yes" phenomenon means AI tools rarely push back on requests, even when they should. A tendency toward confirmation bias - where AI consistently follows the user's direction regardless of merit - can obscure when we've taken a wrong turn, making it increasingly difficult to recognise flawed approaches or dead-end paths.
On a more philosophical note, our group also discussed how AI's outputs come with an unexpected cost: they lack the distinctive character that makes human-written code feel approachable and engaging. There's something to be said for code that bears the fingerprints of its creator - quirky variable names, explanatory comments, elegant workarounds that speak to human creativity.
Domain-Specific Risks: The stakes vary dramatically across research domains. In medical research software, AI-generated errors could impact patient safety decisions. In climate modelling, subtle bugs could affect policy recommendations. High-risk domains require especially careful validation of AI-generated code.
Ethical and Legal Concerns: AI training data can include copyrighted code and personal information scraped from the internet without explicit consent, raising both intellectual property and privacy concerns that remain legally murky [2]. Beyond data collection issues, LLMs can perpetuate and amplify societal biases present in their training data, potentially reinforcing stereotypes related to gender, race, or other sensitive attributes (though this is less relevant to discussions about using AI as coding assistants) [1]. The concentration of AI development in big tech companies also means that access to advanced AI capabilities is increasingly controlled by commercial entities whose priorities may not align with research needs - creating dependencies on proprietary systems where pricing, availability, and development directions are determined by market forces rather than scientific priorities. Interests may not align with research values or democratic principles, potentially giving unethical entities influence over scientific computing infrastructure. Additionally, the opacity of these "black box" models makes it difficult to understand how they arrive at outputs, complicating accountability when errors or biased results occur.
Environmental Impact: The computational costs of AI tools raise serious climate concerns, as training and running large language models require enormous energy consumption. Researchers at the University of Massachusetts, Amherst found that training a large AI model can emit more than 313 tons of carbon dioxide equivalent - nearly five times the lifetime emissions of the average American car, including manufacture of the car itself [3] (note that this 2019 study examined models orders of magnitude smaller than current frontier models). These training emissions, while substantial, are dwarfed by deployment at scale: while individual inference queries have much smaller carbon footprints, GPT-4o inference at 700 million daily queries would generate between 138,125 and 163,441 tons of CO2 annually [5]. The energy demands continue every time the model is used (however, see [4]). Models also show striking disparities in carbon footprint - recent benchmarking [33] shows that the most advanced models produce over 70 times more CO2 per query than efficient alternatives.
It is important to contextualise these emissions: data centres currently account for just 0.5% of global CO2 emissions (with AI comprising about 8% of that, or 0.04% of global emissions) [6]. However, the IEA projects data centres will reach 1-1.4% of global emissions by 2030, with AI's share growing to 35-50% of data centre power. As AI usage continues, the cumulative environmental impact could become substantial, raising questions about alignment with climate goals.
But the Benefits Are Transformative
The productivity gains from AI tools, when used skilfully, can be extraordinary. Since systematic research on RSE-specific contexts is lacking, we rely on evidence from industry and general software development - though many of these benefits are likely to transfer to RSE work.
Multiple studies show developers complete tasks 55-56% faster with AI coding assistants like GitHub Copilot [7, 8]. McKinsey research [12] found documenting code takes half the time, writing new code nearly half the time, and refactoring nearly two-thirds the time. A large-scale study [3] found 26% more completed tasks with 13.5% more commits. However, productivity impacts vary significantly by context and developer experience. A 2025 METR randomised controlled trial [16] found experienced open-source developers took 19% longer when using AI tools on their own repositories - despite believing they were 20% faster. Factors included time reviewing AI code, context switching overhead, and misalignment with project-specific standards in mature codebases. This suggests benefits may be greatest for newer developers or unfamiliar technologies, while experienced developers on complex codebases may see smaller gains.
Research shows mixed but generally positive code quality impacts. GitHub studies [10, 11] found 53.2% greater likelihood of passing unit tests and 13.6% fewer readability errors. However, independent studies like GitClear's research [15] have raised concerns about increased code churn and maintainability issues, indicating quality impact varies based on usage context.
Industry reports suggest significant potential for AI in documentation workflows, including generating technical specifications and API documentation [14]. For RSEs, who often work with research codebases that suffer from inadequate or missing documentation - a common issue in academic software development - AI tools could help generate comprehensive README files and inline comments, making these codebases more accessible to new team members and improving overall code maintainability.
While systematic studies specifically focused on RSE contexts are lacking, making it unclear how these general productivity gains translate to the specialised work that RSEs do, anecdotal reports from our discussion group (and more broadly from RSE community members) indicate that AI tools usually help in one or multiple of the following ways:
- Code generation and completion: Writing new code faster, generating boilerplate, autocompletion.
- Learning and knowledge transfer: Helping understand unfamiliar code, languages, APIs, domain knowledge.
- Code analysis and improvement: Analysing existing codebases, suggesting optimizations, finding issues.
- Documentation and communication: Generating docs, comments, explanations
- Debugging and problem solving: Helping trace issues, explain errors.
Learning and knowledge acceleration deserves special treatment - while AI tools risk deskilling through over-dependence, they also offer perhaps one of the most transformative benefits: the ability to dramatically flatten learning curves. The key lies in how they're used - as a crutch that prevents learning, or as an accelerator that enhances it. Crucially, successful AI use depends heavily on one's ability to evaluate AI outputs. If someone has no foundational knowledge in a domain, they will likely struggle to judge whether AI has solved a task well. The fundamental requirement for effective LLM use is being able to verify whether the AI is providing good responses.
AI serves as an always-available collaborator, particularly valuable for RSEs working in isolation or tackling new technologies, both being a common situation. Studies [2, 9, 13] show that newer and less-experienced developers see the highest adoption rates and greatest productivity gains from AI tools, with research across three domains finding that AI tools significantly narrow the gap between worst and best performers.
For RSEs specifically, this learning acceleration is particularly valuable given the breadth of technologies and domains they typically encounter. AI assistance can enable rapid mastery of new programming languages, understanding legacy scientific codebases faster, and getting up to speed on unfamiliar libraries. The weeks or months required to become productive with a new research tool, domain-specific algorithm, or scientific computing framework can be compressed into days.
This is especially significant for early-career RSEs who may feel overwhelmed by the vast landscape of scientific computing, or for experienced RSEs moving into new research domains where the learning curve has traditionally been steep. The ability to quickly understand and work with unfamiliar codebases, APIs, and domain-specific practices removes a major barrier to contributing effectively across diverse research projects.
Keeping Your Job in an AI-Driven World
Fears and concerns about AI are valid, yet choosing not to engage isn't a viable option. Just as GPS revolutionised navigation while creating new dependencies, AI tools are transforming how we write code while introducing new risks. Experienced users can leverage these tools effectively because they understand when to trust them and when to question their outputs. The challenge lies in ensuring that newcomers develop the underlying skills to recognise when they're being "led into a river."
The Threat
The threat of AI displacement is real and already happening. Recent data shows that 14% of workers have already experienced job displacement due to AI or automation [18], with Goldman Sachs estimating that 6-7% of the US workforce [17] could be displaced if AI is widely adopted. A comprehensive PwC survey spanning 44 countries found that 30% of workers globally fear their jobs could be replaced by AI within the next three years [19]. Entry-level positions face particular risk, with estimates suggesting that AI could impact nearly 50 million US jobs in the coming years [20].
Coding is both where AI currently excels most and where it's improving fastest - telling evidence came in 2024, when software developer employment flatlined after years of consistent growth [22]. According to 80000 Hours [21], within five years, AI will likely surpass humans at coding even for complex projects, with developers transitioning into AI system management roles that blend coding knowledge with other capabilities - though this shift will challenge some.
The Opportunity
Understanding AI's limitations helps identify where human skills remain essential. AI struggles with three categories of tasks [21]: those lacking sufficient training data (like robotics control, which has no equivalent to the internet's vast linguistic datasets), messy long-horizon challenges requiring judgment calls without clear answers over years (like building companies, directing novel research, setting organisational strategy), and situations requiring a person-in-the-loop for, e.g., legal liability or high reliability. Moreover, there are valuable complementary skills when deploying AI: spotting problems, understanding model limitations, writing specifications, grasping user needs, designing AI systems with error checking, coordinating people, ensuring cybersecurity as AI integrates throughout the economy and bearing ultimate responsibility. These skills resemble human management: both difficult for AI to master and complementary to its capabilities. As AI improves, they become more needed, multiplying their value.
As stated previously, while coding represents AI's strongest current capability and its most rapid area of improvement, it has simultaneously made learning to code more accessible and expanded what individual researchers can accomplish. This may increase the value of spending months (rather than years) learning coding as a complementary skill, especially if cheaper production costs expand overall software demand.
80000 Hours’ single most important piece of practical advice for navigating AI-related transitions is to learn to deploy AI to solve real problems. As AI capabilities advance, people who can effectively direct these systems become increasingly powerful. For RSEs, starting points might be using cutting-edge AI tools as coding assistants in their current work, and when opportunities arise, building AI-based applications to address real problems.
The RSE Advantage
We believe RSEs may be uniquely positioned to thrive in an AI-driven world. Unlike pure software development, RSE work requires deep domain expertise, understanding of research methodologies, stakeholder communication and management skills, and the ability to translate evolving scientific requirements into robust software solutions.
Importantly, many of the skills where AI struggles align closely with RSE competencies. RSEs routinely navigate messy long-horizon challenges - directing the software implementation of novel research projects, setting technical strategy for evolving scientific requirements, and making judgment calls where clear answers don't exist. Their work inherently requires a person-in-the-loop for research integrity, reproducibility, and ethical compliance. Moreover, RSEs are particularly well-positioned to develop the complementary skills that become increasingly valuable as AI advances: problem-solve in complex research contexts, write specifications that bridge science and software, grasp diverse user needs across research domains, coordinate interdisciplinary teams, and bear ultimate responsibility for research software reliability. These capabilities - to a huge extent involving project and people management in research contexts - are precisely the skills that AI finds most difficult to replicate and that become more valuable as AI handles more routine coding tasks.
RSEs also operate at the cutting edge of research, where problems are often novel and solutions aren't readily available in LLM training datasets. Just as research itself evolves and adapts, RSEs can leverage their research background to stay ahead of automation. It's precisely in these uncharted territories - where science meets software - that AI tools may remain limited and human insight becomes indispensable.
Essential Skills for the AI Era
- Prompt Engineering: Learning to communicate effectively with AI tools, including crafting prompts that encourage critical evaluation rather than blind compliance.
- AI Literacy: Understanding AI capabilities and limitations, knowing when to use different tools and when tasks can/can not be delegated to an AI agent, and recognising the environmental and ethical implications of various choices.
- Enhanced Validation Practices: AI-generated code may require especially careful validation since errors may not be immediately obvious to human reviewers. Using and extending already existing best development practices, as well as the ability to judge when AI suggestions are leading in the wrong direction, will be crucial.
- Continuous Learning: As AI capabilities evolve rapidly, staying current with both benefits and risks requires ongoing professional development.
Community Actions and Recommendations
The research software community can navigate this transition successfully via:
Training and Education
- Establish foundational AI literacy programs: Help RSEs understand AI capabilities, limitations, and appropriate use cases across different research domains.
- Develop adaptive learning frameworks: Since AI models evolve rapidly and best practices are still emerging, create flexible training approaches that can evolve with the technology rather than rigid curricula that quickly become outdated.
- Foster critical evaluation skills: Train RSEs to assess when AI assistance is helpful versus harmful, and how to validate AI-generated outputs effectively.
Standards and Guidelines
- Develop protocols for disclosing AI assistance in code development and research publications.
- Create environmental impact metrics for AI usage (tools like CodeCarbon can help track computational costs).
- Establish quality standards and validation procedures for AI-generated code in research contexts.
Available Tools and Technologies
The research software community has access to a growing ecosystem of AI tools, each with different strengths:
- Conversational AI Models: ChatGPT, Claude, Gemini, and open-source alternatives like Mistral and DeepSeek offer different capabilities for code generation and problem-solving.
- Integrated Development Tools: CursorAI, GitHub Copilot, and Windsurf provide AI assistance directly within coding environments, while tools like Claude Code, OpenCode and OpenAI's Codex agent enable autonomous coding through various interfaces including command line.
- Local and Specialised Tools: Ollama allows running models locally for sensitive research, while tools like LangChain facilitate building custom AI applications. OpenCode provides terminal-based AI assistance with support for 75+ LLM providers.
- Cloud-Based Autonomous Agents: OpenAI's Codex and Claude Code offer cloud-based software engineering with parallel task execution, while platforms like Manus provide more general-purpose autonomous assistance that can handle coding, among other complex tasks.
The variety of available tools means RSEs can choose solutions that match their security requirements, domain needs, and workflow preferences. Moreover, experienced developers have moved beyond simple chat-based interactions to develop structured workflows for AI-assisted development. Mitchell Hashimoto, for instance, proposes to iteratively build non-trivial features through multiple focused AI sessions, each tackling specific aspects while maintaining human oversight for critical decisions [23]. Geoffrey Litt advocates for a 'surgical' approach where AI handles secondary tasks like documentation and bug fixes asynchronously, freeing developers to focus on core design problems [24]. Peter Steinberger takes this further with parallel AI agents working on different aspects of a codebase simultaneously, using atomic commits and careful prompt engineering to maintain code quality [25]. These workflows share common principles: breaking work into manageable chunks, maintaining clear documentation for AI context, and crucially, always reviewing AI-generated code before deployment.
Conclusion: Looking Forward - Integration, Not Replacement
The expertise in leveraging AI dev tools is being developed primarily in industry, creating a risk that RSEs may fall behind in AI proficiency compared to their industry counterparts. Rather than rejecting AI tools outright, RSEs could position themselves at the forefront of AI usage knowledge, leveraging it to their advantage while actively addressing the legitimate concerns and working to mitigate the risks we've outlined - from deskilling and environmental impact to ethical considerations and quality assurance.
The RSEs who thrive will be those who learn to use AI tools effectively while maintaining the critical thinking, domain expertise, and ethical considerations that define excellent research software. They understand that their value lies not just in writing code, but in asking the right questions, understanding research contexts, and ensuring that software serves scientific discovery. We still need skilled developers who can recognise when they're being led astray.
As we navigate this transition, the research software community can work together to ensure AI enhances rather than replaces the human elements that make RSE work valuable. The question isn't whether AI will change our field (it will and already does) - it's whether we'll shape that change to serve research and society's best interests.
Want to join the conversation? The research software community continues to explore these questions through workshops, training programs, and collaborative initiatives. Visit software.ac.uk to learn more about upcoming events and resources.
Bookmark this page
Bookmarked

Record £10.2m investment to continue improving research software practices
The Software Sustainability Institute (SSI) has been awarded a record £10.2 million funding for a new project phase from 2024-2028 to continue its vital work as the first organisation in the world dedicated to improving software in research.
This project has received funding through the UKRI Digital Research Infrastructure Programme. The Arts and Humanities Research Council (AHRC) leads the funding for the fourth phase of the SSI.
Arts and Humanities Research Council executive chair Christopher Smith said:
“Software plays a fundamental role in all disciplines of research. That’s why it’s so important that we invest in supporting the development of research software that is top quality, meets the needs of our research communities, is environmentally sustainable and is ready for the future. “This record £10.2 million investment is part of the UKRI Digital Research Infrastructure programme’s ongoing investment in evolving existing capability and supporting new infrastructure. It reflects the SSI’s strong track record and the importance of its work for the future of research. I am delighted that AHRC will be hosting this investment for all UKRI communities for the next four years.” |
Transforming research software
This marks the fourth time the SSI has been entrusted with public funding to carry out its mission of transforming research culture by establishing the principle that reliable, reproducible, and reusable software is necessary across all research disciplines.
It achieves this by working with, and investing in, individuals and organisations from across the sector. The SSI’s “collaborate, not compete” ethos has allowed research software to move towards becoming a first class citizen in the research landscape.
“Every modern societal advance is driven by research which relies on software. From weather forecasting to whether we can build new narratives for the next decade, it’s important that we provide equitable access to the digital tools and skills enabling this. This grant - which will see the SSI into its 18th year - enables us to work with the research community to build capability and expertise, ensuring a sustainable future for research software.” — Neil Chue Hong, SSI Director |
SSI-4 focus
The SSI was founded in 2010 as the first organisation in the world dedicated to improving software in research. It is now a world-leading organisation in research software. Phase 4 will focus on tackling the environmental sustainability of research software, investigating how to improve equality, diversity, inclusion and accessibility (EDIA) in the research software community, and addressing the rising interest in Artificial Intelligence (AI) and Machine Learning (ML).
“Over the last 14 years, the SSI has changed research culture around the use of software. I am excited about what we can achieve in the next phase in vital areas such as the environmental impact of software, the use of AI and - most importantly - how we value software as a research output." — Simon Hettrick, SSI Director of Strategy | |
“It’s an incredibly exciting time to be working in the field of Research Software. Over the next few years we are likely to see huge changes in both theory and practice, as AI-based methods gain traction. The environmental sustainability of research software is also a priority, and we look forward to working with our partners and fellows to gather the evidence and develop the policy that will help us to reduce the carbon footprint of computational research.” — Caroline Jay, SSI Director of Research |
For this phase, the SSI is partnering with OLS, a not-for-profit organisation dedicated to diversifying leadership in research, to amplify the impact of the SSI Fellowship Programme. OLS will consult on mentorship training to further develop our Fellows. The SSI will also work closely with the University of Oxford developing strategic activities that strengthen its link to the Arts & Humanities communities.
"The SSI was instrumental in supporting OLS in the early days of our mentorship program, back when we were a fully volunteer effort. Now we're invited back years later as a full partner to consult on our mentorship expertise. This speaks volumes for the SSI's commitment to cultivating and supporting their community. We couldn't be more excited to give back by helping grow the next generation of Fellows and their mentors!" — Yo Yehudi, OLS Director | |
“Oxford has been proud to support the SSI since 2010, engaging particularly with the Arts, Humanities and Cultural Heritage communities and focusing on national research infrastructure and shaping data and software policy. The Digital Scholarship at Oxford team is very excited to help further these strategic activites as SSI enters Phase 4, with digital tools and software continuing to transform how data is collected, analysed, managed, shared and sustained for future generations.” — David DeRoure, Academic Director of Digital Scholarship, Oxford University |
The SSI is led by EPCC at the University of Edinburgh in partnership with the universities of Manchester and Southampton. It was founded in 2010 thanks to funding from the UKRI Engineering and Physical Sciences Research Council (EPSRC). In 2016, the UKRI Economic and Social Research Council (ESRC) and the UKRI Biotechnology and Biological Sciences Research Council (BBSRC) joined EPSRC to further invest and help continue the work of the SSI throughout its second phase. The third phase was funded by all UKRI research councils.
Bookmark this page
Bookmarked

Research software is critical to the future of AI-driven research
Estimated read time: 23 min
Sections in this article
Research software is critical to the future of AI-driven research
This blog was originally posted on the Research Software Alliance website and has been cross-posted by the Netherlands eScience Center, and US-RSE. The publication can be accessed on Zenodo (DOI 10.5281/zenodo.13350747).
Abstract
This position paper provides a statement on the criticality of research software in artificial intelligence (AI)-driven research and makes recommendations for stakeholders on how to consider research software in their AI goals. This is needed to ensure that the focus on technological infrastructure to support AI acceleration includes research software and its personnel as a vital part of that infrastructure. This paper discusses both research software that supports generative AI, which is now being explored today as a tool to enable new research, as well as more traditional machine learning, which has demonstrated impact in research in most disciplines (particularly in the last decade).
This paper begins by providing definitions for key terms and demonstrating the importance of research software in AI-driven research. The paper then explores the need for AI strategies to recognise research software as key building blocks of AI-driven research, and to include this element alongside a focus on computing systems, data, and models. The fact that AI is dependent on software (i.e., data preparation and model training are performed by software, models are implemented in software) is not always adequately considered. Alongside this high level need for incorporation of research software in AI strategies, the challenges inherent in software dependencies also need consideration, as research software requires continual maintenance, updating, bug fixes, etc. Consequently, the broader challenges in enabling ongoing support for research software used for any type of research are equally relevant to AI-driven research and presented here.
There is also a need to better support the people who develop and maintain the research software that enables AI-driven research. Because human skills, training, and career paths often feature in AI strategies, it is imperative that stakeholders facilitate practices that support and recognise research software personnel. And while the research community is exploring how to leverage AI to improve how research software is developed and maintained, this is also affecting how research software practices should be taught. The paper also illustrates how some countries are operationalising AI strategies that could support the critical element of research software, and have the potential to do so by building on existing investments in research software.
This paper was written as a collaboration between the Research Software Alliance (ReSA) and the Digital Research Alliance of Canada, one of ReSA’s Founding Members. ReSA is a global organisation that unites decision-makers and influencers across the international research software community.
The Digital Research Alliance of Canada is funded by the Government of Canada to serve Canadian researchers, including the infrastructure and activities required for research software. Other community leaders also provided inputs from institutional and open source perspectives.
1. Introduction
This position paper provides a statement on the criticality of research software in artificial intelligence (AI)-driven research. This is needed to ensure that the focus on technological infrastructure to support AI acceleration includes research software - a vital part of that infrastructure. This paper begins by providing definitions for key terms, demonstrating the importance of research software in AI-driven research, and explaining why this paper was developed. The paper then explores the need for AI strategies to recognise research software as a key building block of the AI-driven research, and to include this element alongside a focus on computing systems, data, and models. To do this, evidence on the issues in supporting research software, including open-source scientific software, are presented.
The paper then explores how to better support the people who develop and maintain the research software in AI-driven research. AI strategies often consider people elements such as skills and career paths, which also reflect broader issues for personnel. The paper then illustrates how some countries are operationalising AI strategies that could support the critical element of research software, and have the potential to do so by building on existing investments in research software. Finally, the paper makes recommendations for stakeholders to consider research software in their AI strategies.
2. What is research software and why is it critical to AI?
Research software is defined in accordance with the FAIR for Research Software Principles (Barker et al. 2022) as “source code files, algorithms, scripts, computational workflows and executables that were created during the research process or for a research purpose. Software components (e.g., operating systems, libraries, dependencies, packages, scripts, etc.) that are used for research but were not created during or with a clear research intent should be considered software in research and not research software. This differentiation may vary between disciplines” (Gruenpeter et al. 2021).
Research software supports AI, both 1) in more traditional machine learning (ML), where models are trained on data and then used to infer knowledge about new data, and 2) in generative AI, which can be defined as “deep-learning models that can generate high quality text, images, and other content based on the data they were trained on” (Martineau 2021).
Research software is already recognised as critical to research outcomes (Barker, Katz, and Gonzalez-Beltran 2020; Hocquet et al. 2024; Strasser et al. 2022). Research software can be a research output in itself, and its many functions range from being a component of research instruments, being the research instrument (where research software generates research data, validates research data, or tests hypotheses, such as models and simulations), analysing and presenting research data, and providing infrastructure or underlying tools (Nieuwpoort and Katz 2024). All machine learning (ML) and AI began as research software. In many cases AI research software has transitioned outside of research and is widely used outside research today.
Consequently, research software is essential in AI-based research, where newly developed methods are research software. Some AI reports and strategies recognise this; for example, OECD’s Artificial Intelligence in Science report (OECD 2023) highlights the need to better support research software as part of utilising AI to accelerate scientific productivity, in a number of ways, including:
- Increase access to software
- Share best practices and applications of research software
- Facilitate more regular funding and more secure positions
- Improve ways to measure research impact and productivity
- Consider academic training changes needed
- Utilise disciplinary consortiums to accelerate discovery and improve reproducibility through sharing of software
- Understand how AI can speed up research software development
The research community personnel who develop and maintain research software are just as important as the research software itself, if not more important, as the software will stop working without ongoing maintenance. This maintenance is needed 1) to respond to bugs so that the software continues to be correct, 2) to add new features so that the software continues to be useful as research progresses, 3) to adapt to change in underlying software and hardware or in related software ecosystems, such as changed libraries and computing systems, so that the software continues to work.
The people who do this work can have many titles, including researchers, research software engineers (RSEs), data scientists, computer scientists, data engineers, bioinformaticians, students, community scientists, and many more (Hettrick et al. 2022; Barker and Buchhorn 2022). The inclusion of improved support for the staff who develop and maintain research software is also emphasised in the UK-focused Review of Digital Research Infrastructure Requirements for AI (Lazauskas et al. 2022). This report’s findings included emphasis that “any investment in any infrastructure for AI would need to be matched by investments in training and support”, with the second highest priority areas identified as funding for RSEs (Lazauskas et al. 2022). The UK’s ExCALIBUR RSE Knowledge Integration Landscape Review also highlights the need for RSEs to acquire new skills relevant to AI, and notes that “These skill sets also begin to deviate from what is demanded by industries, requiring novel AI software and capabilities'' (Parsons et al. 2021).
ReSA’s initial research on recognition of research software in the AI landscape was presented in March 2024 at its Research Software Funders Forum meetings. This forum engages representatives from over 60 funding organisations in online meetings and hybrid venues (ReSA 2024a). Attendees of these March meetings were immediately able to utilise these early findings from the presentation to strengthen their own cases for investment in research software within AI-dominated programs, where the criticality of this building block is not yet understood by many in their organisations. It became clear that further research on best practices would support not only funders, but a variety of stakeholders in the international research software community.
The research in this position paper was undertaken as a partnership between ReSA and the Digital Research Alliance of Canada, one of ReSA’s Founding Members. One of ReSA’s key functions is to ensure that research software is considered in international discussions on how to advance research capabilities. ReSA is a global organisation that unites decision-makers and influencers across the international research software community. The Digital Research Alliance of Canada is a non-profit organisation funded by the Government of Canada. It advances Canada’s position as a leader in the knowledge economy on the international stage by integrating, championing and funding the infrastructure and activities required, with research software as one of the three main areas. Other community leaders were also brought in on this paper in order to present more balanced perspectives on the need for research software in AI, particularly from institutional and open source perspectives.
3. Consequences if research software is not supported
There is a tendency for AI initiatives to minimise or exclude focus on research software. This minimisation creates challenges. To show this, evidence on the issues in supporting research software, including open-source scientific software, is also presented here.
Many AI initiatives tend to focus on computing systems, data, and models, considering issues such as availability of systems that can train models and use them for inference in reasonable time periods; FAIRness of underlying data as well as its suitability for training models, including regularity and labelling; understanding and reducing bias in data and models; and understanding privacy. The fact that AI models are implemented in software, and that software is required for training, is rarely considered. Basically, models are thought of as extensions of data, not of software as well. Consequently, many AI strategies focus on data and models, but exclude the underlying software. An example of an AI strategy that does not necessarily adequately include a research software focus include the US National Institutes of Health (NIH) workshop, Towards an ethical framework for AI in biomedical and behavioural research, which focused on data and models, but not the research software inherent in using the data and models (ODSS 2024).
This challenge is not limited to research software. Discussions of AI capacity often omit open source software, instead focusing on areas such as talent, funding, data, semiconductors, and compute access (Engler 2021). Like research software, open source software can advance science, but also has significant effects in other areas such as development of AI standards (Engler 2021). Further, research software is often either open source itself or depends on open source software. But considerations for software from AI initiatives, if any, do not normally include open source software maintenance as a priority, nor analysis of its dependency on other software (Nahar et al. Forthcoming). Where dependency analysis does happen, it is usually due to concerns about supply chain security or perceived attack vectors (a pathway or method used to access a network or computer to attempt to exploit system vulnerabilities).
The nature of open source software as a complex stack, and the concomitant extra step of funding those open source software dependencies of the research software necessary for AI is largely ignored. This could reflect a misunderstanding of how open source dependencies introduce systemic vulnerabilities that need to be addressed and maintained on an ongoing basis, or concerns regarding funding many independent projects down the dependency tree. When open source software is used without planning for future community or dependency support, the result is a more brittle system in the long run – for research software, open source software, and AI.
There has been some recent work done on software bills of materials (SBOMs) in open source supply chains, where dependencies are charted out, in part so that their vulnerabilities can be understood (National Security Agency 2024; SCAWG 2022) (and it is relevant to note that research software is often used to map these dependencies). Mapping supply chains is increasingly important for understanding how to shore up digital infrastructure, where large economies depend upon open source software that is poorly maintained and that may be internationally broken or hijacked, or may break (as in the XZ Utils, Heartbleed, or the Log4j incidents (Goodin 2024; Buchanan 2021), or the more recent CrowdStrike failure which caused a global Windows outage (Robins-Early 2024)). However, SBOMs are merely an atlas for understanding dependencies – they are policy agnostic and their creation doesn’t mandate funding or supporting important open source or research software.
This paper suggests that infrastructural issues with using and supporting open source software are similar or identical to issues with using research software. Where AI is involved, the same questions of continued support for the research software being used to develop, train, and run the AI systems are raised. Any AI initiative that plans to use global infrastructure, to adapt to new fields and target areas, or which hopes to exist for the long haul must consider the research software that enables those goals.
4. Challenges if research software personnel are not supported
There is also a need to better support the people who develop and maintain research software that is important to AI-driven research. This is recognised in relation to research software personnel in general, particularly in relation to the training, hiring, and funding of both professional research and technical staff able to reuse, develop, and maintain sustainable research software; appropriate reward and recognition measures that enable career progression for all people involved in the creation and maintenance of research software; and citation practices for research software that recognise substantial contributors to all aspects of the software (Van Tuyl 2023; US-RSE Association and IEEE Computer Society 2023; Barker and Katz 2022a; ReSA 2023). For example, Software and skills for research computing in the UK recommendations include facilitating detailed analysis of how to professionalise RSE roles; and collaboration between government, funders, and employers to create national policies aimed at improving standards of employment (Barker et al. 2024).
Whilst many of the issues for research software in general are the same for research software to support AI-driven research, one area of difference is in the specifics of skills and training. Human skills, training, and career paths often feature in AI strategies, and it is important that these focus on relevant research software practices. For example, the Review of Digital Research Infrastructure Requirements for AI specifically emphasises the lack of AI skills and training, and career paths for research personnel, including for RSEs. It highlights that these staff often lack formal training, and ongoing professional development is crucial in the fast-paced world of AI tools and techniques (Lazauskas et al. 2022). With many researchers now using GenAI for coding tasks (Nordling 2023, cited in Hosseini et al. 2024), software development skills need to change to reflect this (Caballar 2024; Dursi 2024).
5. National approaches
AI is now seen as a geopolitical asset, and as international organisations and a range of countries seek to show leadership for AI in science, some countries are operationalising AI strategies that could support the critical element of research software. However, more focus is needed. One example of discussing software within a national AI strategy is the US National Artificial Intelligence Research Resource (NAIRR). NAIRR aims to provide a shared national research infrastructure for responsible discovery and innovation in AI, to address the fact that many researchers lack the necessary access to the computing, data, software and educational resources needed. The NAIRR pilot’s four operational focus areas include one area dedicated to software, to “facilitate and investigate interoperable use of AI software, platforms, tools and services for NAIRR pilot resources” (NSF 2024). However, there are potential challenges with this approach as the focus is on interoperability of existing software, which assumes that sustainable software is already in place.
Many countries also have existing investments in research software (Barker and Katz 2022b; ReSA 2024b) that national initiatives have the potential to build on. The UK’s AI Research Resource (AIRR) is another example of a national initiative, which focuses on increasing computational power to support AI-driven research (UKRI 2023), although its funding is now uncertain (Trueman 2024). Whilst AIRR does not seem to include a focus on research software, AIRR is a key component of UK Research and Innovation (UKRI)’s Digital Research Infrastructure (DRI) which has featured a number of recent investments in research software, including funding of research technical professionals (RTPs), such as RSEs. For example, the Engineering and Physical Sciences Research Council (EPSRC) and UKRI DRI have invested £16 million to support community-driven projects providing training and development for RTPs (UKRI 2024a). UKRI’s Digital RTP Skills NetworkPlus aims to explore key challenges and interventions related to skills and careers that are faced by digital RTP communities across the UK research and innovation landscape (UKRI 2024b).
Canada has been a leader in AI, as the first country in the world to put in place in 2017 a fully-funded AI strategy, the Pan-Canadian AI Strategy (ISED 2022). The strategy included establishment of a national program of research chairs to recruit and retain top researchers at Canadian universities, establishment of three national AI institutes to be global centres of training and research excellence, and the creation of a Pan-Canadian AI Compute Environment (PAICE) platform. The Digital Research Alliance of Canada’s National Research Software Strategy for 2025-2030 (Digital Research Alliance of Canada, National Research Software Strategy Working Group 2023) also reviewed (inter)national research software funding programs in support of AI, deep learning, and ML-facilitated research. Before the Alliance, CANARIE has been a national Research Software funder and service provider since 2007, whose successful research software initiatives had resulted in the development of sophisticated software tools, known as research platforms, that typically support end-to-end research workflow within a specific domain. New platforms re-used software components previously developed through CANARIE funding, and contributed additional components back to the research community, creating a powerful cycle of software development and reuse (CANARIE 2024). The Alliance is now using the Research Software Directory to continue promoting the visibility, impact, and reuse of the Canadian research software (Digital Research Alliance of Canada 2024).
6. Recommendations for research software to support AI
Research software needs to be included in AI strategies. Our recommendations for doing so are listed below, organised in three areas from the Amsterdam Declaration on Funding Research Software Sustainability (ReSA 2023):
Research software practice:
a. AI strategies and funding must recognise that research software is a key part of the (publicly funded) AI pipeline and that AI is dependent on software, and therefore should stimulate the development and maintenance of research software to ensure the success of the AI work.
Research software ecosystem:
a. Because AI-driven research is dependent on the existing research software ecosystem, AI strategies should provide long-term support for its elements, including personnel, communities, and infrastructure, and should add new elements that focus on AI-specific parts as needed.
Research software personnel:
a. Because the existing research software ecosystem that supports AI-driven research is dependent on research software personnel, AI strategies should facilitate appropriate reward and recognition measures that enable career progression for all people involved in the creation and maintenance of research software that supports AI- driven research.
Other ways to help ensure that the focus on technological infrastructure to support AI acceleration includes research software and its personnel as a vital part of that infrastructure include:
- Signing the Amsterdam Declaration on Funding Research Software Sustainability (ADORE.software), which represents a first step to formalise, on a global level, the basic principles and recommendations related to funding the sustainability of research software, including the people needed to achieve this goal.
- Supporting ReSA in its aim to ensure that research software is considered in international discussions on how to advance research capabilities. Become a ReSA Organisational Member, support a task force, or donate.
- For funders, joining the Research Software Funders Forum, a global collaboration of funding organisations committed to supporting research software, and those who develop and maintain it, as fundamental and vital to research.
References
Barker, Michelle, Elena Breitmoser, Philippa Broadbent, Neil Chue Hong, Simon Hettrick, Ioanna Lampaki, Anthony Quinn, and Rebecca Taylor. 2024. ‘Software and Skills for Research Computing in the UK’. Zenodo. https://doi.org/10.5281/ZENODO.10473186.
Barker, Michelle, and Markus Buchhorn. 2022. ‘Research Software Capability in Australia’. Zenodo. https://doi.org/10.5281/ZENODO.6335998.
Barker, Michelle, Neil P. Chue Hong, Daniel S. Katz, Anna-Lena Lamprecht, Carlos Martinez-Ortiz, Fotis Psomopoulos, Jennifer Harrow, et al. 2022. ‘Introducing the FAIR Principles for Research Software’. Scientific Data 9 (1): 622. https://doi.org/10.1038/s41597-022-01710-x.
Barker, Michelle, and Daniel S Katz. 2022a. ‘Encouraging Entry, Retention, Diversity and Inclusion in Research Software Careers’. https://doi.org/10.5281/ZENODO.7117842.
Barker, Michelle, and Daniel S. Katz. 2022b. ‘Overview of Research Software Funding Landscape’, February. https://doi.org/10.5281/ZENODO.6102487.
Barker, Michelle, Daniel S. Katz, and Alejandra Gonzalez-Beltran. 2020. ‘Evidence for the Importance of Research Software’. Zenodo. https://doi.org/10.5281/ZENODO.3884311.
Buchanan, Bill. 2021. ‘Log4j: The Worst Vulnerability In Nearly A Decade?’ Medium (blog). 2021. https://medium.com/asecuritysite-when-bob-met-alice/log4j-the-worst-vulnerability-in-nearly-a-decade-e0cc80cbb49a.
Caballar, Rina Diane. 2024. ‘AI Copilots Are Changing How Coding Is Taught - IEEE Spectrum’. 2 May 2024. https://spectrum.ieee.org/ai-coding.
CANARIE. 2024. ‘Funded Research Software Platforms’. 2024. https://www.canarie.ca/software/platforms/.
Digital Research Alliance of Canada. 2024. ‘Research Software Directory’. 2024. https://research-software-directory.org/organisations/digital-research-alliance-of-canada?tab=software&order=is_featured.
Digital Research Alliance of Canada, National Research Software Strategy Working Group. 2023. ‘National Research Software Strategy 2023’. Zenodo. https://doi.org/10.5281/ZENODO.10214741.
Dursi, Jonathan. 2024. ‘We Need To Talk About AI’. Research Computing Teams 183 (June). https://newsletter.researchcomputingteams.org/archive/rct-183-we-need-to-talk-about-ai-plus-upfront/.
Engler, Alex. 2021. ‘How Open-Source Software Shapes AI Policy’. Brookings. 10 August 2021. https://www.brookings.edu/articles/how-open-source-software-shapes-ai-policy/.
Goodin, Dan. 2024. ‘The XZ Backdoor: Everything You Need to Know’. Wired. 2 April 2024. https://www.wired.com/story/xz-backdoor-everything-you-need-to-know/.
Gruenpeter, Morane, Daniel S. Katz, Anna-Lena Lamprecht, Tom Honeyman, Daniel Garijo, Alexander Struck, Anna Niehues, et al. 2021. ‘Defining Research Software: A Controversial Discussion’. Zenodo. https://doi.org/10.5281/ZENODO.5504016.
Hettrick, Simon, Radovan Bast, Steve Crouch, Claire Bradley, Philippe, Botzki, Alex, Carver, Jeffrey, et al. 2022. ‘International RSE Survey 2022’. https://softwaresaved.github.io/international-survey-2022/. https://doi.org/10.5281/ZENODO.6884882.
Hocquet, Alexandre, Frédéric Wieber, Gabriele Gramelsberger, Konrad Hinsen, Markus Diesmann, Fernando Pasquini Santos, Catharina Landström, et al. 2024. ‘Software in Science Is Ubiquitous yet Overlooked’. Nature Computational Science, July. https://doi.org/10.1038/s43588-024-00651-2.
ISED. 2022. ‘Pan-Canadian Artificial Intelligence Strategy’. Home page; Innovation, Science and Economic Development Canada. 20 July 2022. https://ised-isde.canada.ca/site/ai-strategy/en/pan-canadian-artificial-intelligence-strategy.
Lazauskas, Tomas, Jennifer Ding, Neil Brown, Reda Nausedaite, Felix Dijkstal, Aaron Vinnik, Bruno Raabe, et al. 2022. ‘Review of Digital Research Infrastructure Requirements for AI’. https://doi.org/10.13140/RG.2.2.29376.00009.
Martineau, Kim. 2021. ‘What Is Generative AI?’ IBM Research. 9 February 2021. https://research.ibm.com/blog/what-is-generative-AI.
Nahar, Nadia, Haoran Zhang, Grace Lewis, Shurui Zhou, and Christian Kästner. Forthcoming. ‘The Product Beyond the Model - An Empirical Study of Repositories of Open-Source ML Products’. In . https://www.cs.cmu.edu/~ckaestne/publications.html.
National Security Agency. 2024. ‘Recommendations for Software Bill of Materials (SBOM) Management’. https://media.defense.gov/2023/Dec/14/2003359097/-1/-1/0/CSI-SCRM-SBOM-MANAGEMENT.PDF.
Nordling, Linda. 2023. ‘How ChatGPT Is Transforming the Postdoc Experience’. Nature 622 (7983): 655–57. https://doi.org/10.1038/d41586-023-03235-8.
NSF. 2024. ‘National Artificial Intelligence Research Resource Pilot’. 2024. https://new.nsf.gov/focus-areas/artificial-intelligence/nairr.
ODSS. 2024. ‘Toward an Ethical Framework for AI in Biomedical and Behavioral Research’. 2024. https://www.scgcorp.com/ethicalframework2024/Agenda.
OECD. 2023. Artificial Intelligence in Science: Challenges, Opportunities and the Future of Research. OECD. https://doi.org/10.1787/a8d820bd-en.
Parsons, Mark, Alastair Basden, Richard Bower, Neil P. Chue Hong, Davide Constanzo, Shaun Witt, Luigi Del Debbio, et al. 2021. ‘ExCALIBUR Research Software Engineer Knowledge Integration Landscape Review’. Zenodo. https://doi.org/10.5281/ZENODO.4986062.
ReSA. 2023. ‘Amsterdam Declaration on Funding Research Software Sustainability’, August. https://doi.org/10.5281/ZENODO.8325436.
———. 2024a. ‘Research Software Funders Forum’. 2024. https://researchsoft.org/funders-forum/.
———. 2024b. ‘Research Software Funding Opportunities’. 2024. https://researchsoft.org/funding-opportunities/.
Robins-Early, Nick. 2024. ‘What Is CrowdStrike, and How Did It Cause a Global Windows Outage?’ The Guardian, 19 July 2024. https://www.theguardian.com/technology/article/2024/jul/19/what-is-crowdstrike-microsoft-windows-outage.
SCAWG. 2022. ‘Recommendations to Improve the Resilience of Canada’s Digital Supply Chain’. https://ised-isde.canada.ca/site/spectrum-management-telecommunications/sites/default/files/attachments/2022/CFDIR-June2022-recommendations.pdf.
Strasser, Carly, Kate Hertweck, Josh Greenberg, Dario Taraborelli, and Elizabeth Vu. 2022. ‘10 Simple Rules for Funding Scientific Open Source Software’, June. https://doi.org/10.5281/ZENODO.6611500.
Trueman, Charlotte. 2024. ‘UK Government Shelves £1.3bn of Tech and AI Projects; Scraps Plans for First Exascale Supercomputer in Edinburgh’. 2 August 2024. https://www.datacenterdynamics.com/en/news/uk-government-shelves-13bn-of-tech-and-ai-projects-scraps-plans-for-first-exascale-supercomputer-in-edinburgh/.
UKRI. 2023. ‘£300 Million to Launch First Phase of New AI Research Resource’. 1 November 2023. https://www.ukri.org/news/300-million-to-launch-first-phase-of-new-ai-research-resource/.
———. 2024a. ‘New Funding to Support Research Technical Professionals’. 18 March 2024. https://www.ukri.org/news/new-funding-to-support-research-technical-professionals/.
———. 2024b. ‘UKRI Digital Research Technical Professional Skills NetworkPlus’. 22 April 2024. https://www.ukri.org/opportunity/ukri-digital-research-technical-professional-skills-networkplus/.
US-RSE Association and IEEE Computer Society. 2023. ‘Research Software Engineers: Creating a Career Path—and a Career’. Zenodo. https://doi.org/10.5281/ZENODO.10073232.
Van Tuyl, Steve (Ed.). 2023. ‘Hiring, Managing, and Retaining Data Scientists and Research Software Engineers in Academia: A Career Guidebook from ADSA and US-RSE’. Zenodo. https://doi.org/10.5281/ZENODO.8274378.
Bookmark this page
Bookmarked

BioModelsML Hackathon: Making Machine Learning Models FAIR and Reproducible
The BioModels ML Hackathon will take place remotely on the 20 and 21 June and focus on applying FAIR principles to machine learning models in the life sciences, enhancing their reproducibility and utility.
Participants will be able to:
- Engage in hands-on activities to make ML models more Findable, Accessible, Interoperable, and Reusable.
- Collaborate with experts and peers to boost the impact of your work.
- Contribute to a leading community resource while gaining recognition for your expertise.
The hackathon is ideal for researchers, data scientists, and developers at the intersection of AI/ML and life sciences.
Bookmark this page
Bookmarked

Registration open for AI Replication Game at the University of Sheffield
The Institute for Replication (I4R) and the University of Sheffield will be organising the AI Replication Game at the University of Sheffield on Monday 17 June 2024 from 9.14 AM to 4 PM. This one-day event aims to bring researchers together to collaborate on reproducing quantitative results published in high-ranking social science journals. By taking part in the Replication Game, participants will not only contribute to the integrity of research in their field but also have the opportunity to network with fellow researchers and develop their coding and AI skills.
Researchers participating in the AI Replication Game will be randomly assigned to one of three teams: Machine, Cyborg or Human. Machine and Cyborg teams will have access to (commercially available) LLM models to conduct their work; Human teams will rely only on unaugmented human skills. Teams will be asked to check for coding errors and conduct a robustness reproduction, which is the ability to duplicate the results of a prior study using the same data but different procedures. During the event, participants are expected to read the paper and familiarise themselves with the code and data shared alongside the paper. Teams will then work together to check for coding errors and conduct sensitivity analysis. No work is conducted before/after the event other than answering a short survey.
All participants will get coauthorship on a metaresearch journal paper which combines the work of all teams.
The Replication Game is open to all researchers: academics, post-docs, and graduate students. Knowledge of Python or R is essential.
For more information and to register for the AI Replication Game, please follow the link below. The deadline for registration is Saturday 1 June.